TopicRank
2020-09-07
实现项目 https://github.com/boudinfl/pke
因此一定要基于nltk和spacy
python -m nltk.downloader stopwords
python -m nltk.downloader universal_tagset
python -m spacy download en # download the english modelKeyphrase extraction is the task of identifying single or multi-word expressions that represent the main topics of a document.
正是我想要的,如果能够匹配到正则化的程度就更好的,这个估计需要构建一个语言模型才好。
In this paper we present TopicRank, a graph-based keyphrase extraction method that relies on a topical representation of the document.
不确定是不是GNN的网络。
Candidate keyphrases are clustered into topics and used as vertices in a complete graph.
这是一个特定的图。
A graph-based ranking model is applied to assign a significance score to each topic. Keyphrases are then generated by selecting a candidate from each of the topranked topics.
关键词和语句提取的方式。
We conducted experiments on four evaluation datasets of different languages and domains. Results show that TopicRank significantly outperforms state-of-the-art methods on three datasets.
了解 sota 的评价指标和如何设计任务。
0.1 Introduction
Keyphrases are single or multi-word expressions that represent the main topics of a document. Keyphrases are useful in many tasks such as information retrieval (Medelyan and Witten, 2008 ), document summarization (Litvak and Last, 2008 ) or document clustering (Han et al.,2007).
Keyphrases 很有用。
Although scientific articles usually provide them, most of the documents have no associated keyphrases. Therefore, the problem of automatically assigning keyphrases to documents is an active field of research.
但是文档对应的关键短语还没有研究做。
Automatic keyphrase extraction methods are divided into two categories: supervised and unsupervised methods. Supervised methods recast keyphrase extraction as a binary classification task (Witten et al., 1999), whereas unsupervised methods apply different kinds of techniques such as language modeling (Tomokiyo and Hurst, 2003 ), clustering (Liu et al., 2009 ) or graph-based ranking (Mihalcea and Tarau, 2004).
我们必然是查看无监督的关键短语提取。
In this paper, we present a new unsupervised method called TopicRank. This new method is an improvement of the TextRank method applied to keyphrase extraction (Mihalcea and Tarau, 2004). In the TextRank method, a document is represented by a graph where words are vertices and edges represent co-occurrence relations. A graph-based ranking model derived from PageRank (Brin and Page, 1998) is then used to assign a significance score to each word. Here, we propose to represent a document as a complete graph where vertices are not words but topics. We define a topic as a cluster of similar single and multiword expressions.
PageRank -> TextRank -> TopicRank 而已,文本摘要真的是我想要的么?我可以试试。
Our approach has several advantages over TextRank. Intuitively, ranking topics instead of words is a more straightforward way to identify the set of keyphrases that covers the main topics of a document. To do so, we simply select a keyphrase candidate from each of the top-ranked clusters. Clustering keyphrase candidates into topics also eliminates redundancy while reinforcing edges. This is very important because the ranking performance strongly depends on the conciseness of the graph, as well as its ability to precisely represent semantic relations within a document. Hence, another advantage of our approach is the use of a complete graph that better captures the semantic relations between topics.
一个文档提取一个关键语句。
- 为什么说这个是 graph-based method?
Bougouin, Boudin, and Daille (2013) 用多个数据集进行了方法对比,包括了 TF-IDF、TextRank。
To evaluate TopicRank, we follow Hasan and Ng (2010) who stated that multiple datasets must be used to evaluate and fully understand the strengths and weaknesses of a method. We use four evaluation datasets of different languages, document sizes and domains, and compare the keyphrases extracted by TopicRank against three baselines (TF-IDF and two graph-based methods). TopicRank outperforms the baselines on three of the datasets.
As for the fourth one, an additional experiment shows that an improvement could be achieved with a more effective selection strategy.
Bougouin, Boudin, and Daille (2013) 还给出了一定的 tricks。
The rest of this paper is organized as follows. Section 2 presents the existing methods for the keyphrase extraction task, Section 3 details our proposed approach, Section 4 describes the evaluation process and Section 5 shows the analyzed results. Finally, Section 6 concludes this work and suggests directions for future work.
查阅前任经验、 Bougouin, Boudin, and Daille (2013) 方法、实验结构、后续改良的建议。
0.3 TopicRank
TopicRank is an unsupervised method that aims to extract keyphrases from the most important topics of a document. Topics are defined as clusters of similar keyphrase candidates. Extracting keyphrases from a document consists in the following steps, illustrated in Figure 1. First, the document is preprocessed (sentence segmentation, word tokenization and Part-of-Speech tagging) and keyphrase candidates are clustered into topics. Then, topics are ranked according to their importance in the document and keyphrases are extracted by selecting one keyphrase candidate for each of the most important topics.
一个文档构建若干个主题,每个主题构建出一个最相关的关键短语。
Section 3.1 first explains how the topics are identified within a document, section 3.2 presents the approach we use to rank them and section 3.3 describes the keyphrase selection.
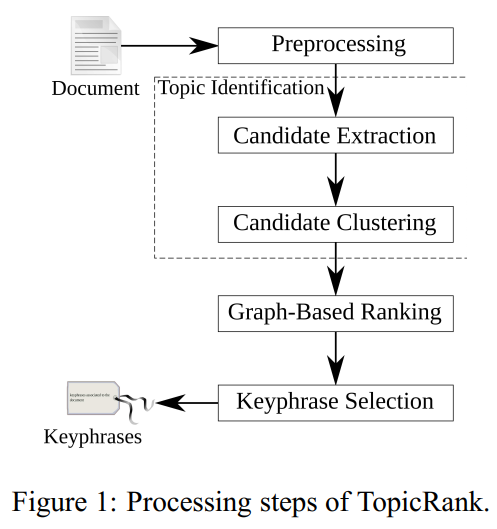
Figure 1: 因此主题识别、主题排序、关键语句提取三步是先后完成的。
0.3.1 Topic Identification
Keyphrases describe the most important topics of a document, thus the first step is to identify the keyphrase candidates that represent them. Hulth (2003) stated that most keyphrases assigned by human readers are noun phrases. Hence, the most important topics of a document can be found by extracting their most significant noun phrases. We follow Wan and Xiao (2008) and extract the longest sequences of nouns and adjectives from the document as keyphrase candidates.
最关键的短语还是以名词为主。 Bougouin, Boudin, and Daille (2013) 采用名词+形容词为主要信息来源。
Other methods use syntactically filtered n-grams that are most likely to contain a larger number of candidates matching with reference keyphrases, but the n-gram restricted length is a problem. Indeed, ngrams do not always capture as much information as the longest noun phrases. Also, they are less likely to be grammatically correct.
Bougouin, Boudin, and Daille (2013) 放弃 n-grams,因为最长的句子不代表信息最多,因此这么分析, Bougouin, Boudin, and Daille (2013) 猜想是存在语法错误的。
In a document, a topic is usually conveyed by more than one noun phrase. Consequently, some keyphrase candidates are redundant in regard to the topic they represent. Existing graph-based methods (TextRank, SingleRank, etc.) do not take that fact into account. Keyphrase candidates are usually treated independently and the information about the topic they represent is scattered throughout the graph. Thus, we propose to group similar noun phrases as a single entity, a topic.
一般一个主题里面可以存在多个关键短语候选,这是 TextRank 和 SingleRank 尚未解决的问题,TopicRank 打算使用“组”的思想,或者在生产中,这种方法更实际的提取关键词。
We consider that two keyphrase candidates are similar if they have at least \(25 \%\) of overlapping words1. Keyphrase candidates are stemmed to reduce their inflected word forms into root forms.2 To automatically group similar candidates into topics, we use a Hierarchical Agglomerative Clustering (HAC) algorithm. Among the commonly used linkage strategies, which are complete, average and single linkage, we use the average linkage, because it stands as a compromise between complete and single linkage. In fact, using a highly agglomerative strategy such as complete linkage is more likely to group topically unrelated keyphrase candidates, whereas a strategy such as single linkage is less likely to group topically related keyphrase candidates.
- 这一段实际上没有看懂,用到了层次聚类,但是其中 linkage 算法的优劣,因为不了解这一类,因此不明白
0.3.2 Graph-Based Ranking
TopicRank represents a document by a complete graph in which topics are vertices and edges are weighted according to the strength of the semantic relations between vertices. Then, TextRank’s graph-based ranking model is used to assign a significance score to each topic.
这里使用 TextRank 的思想。
0.3.2.1 Graph Construction
这个风格,就是概率图模型,之前在 CRF 和周志华的概率图模型章节(主题模型也算在其中) 看到过。
Formally, let \(G=(V, E)\) be a complete and undirected graph where \(V\) is a set of vertices and the edges \(E\) a subset of \(V \times V\). Vertices are topics and the edge between two topics \(t_{i}\) and \(t_{j}\) is weighted according to the strength of their semantic relation. \(t_{i}\) and \(t_{j}\) have a strong semantic relation if their keyphrase candidates often appear close to each other in the document. Therefore, the weight \(w_{i, j}\) of their edge is defined as follows:
\[ \begin{aligned} w_{i, j} &=\sum_{c_{i} \in t_{i}} \sum_{c_{j} \in t_{j}} \operatorname{dist}\left(c_{i}, c_{j}\right) \\ \operatorname{dist}\left(c_{i}, c_{j}\right) &=\sum_{p_{i} \in \operatorname{pos}\left(c_{i}\right)} \sum_{p_{j} \in \operatorname{pos}\left(c_{j}\right)} \frac{1}{\left|p_{i}-p_{j}\right|} \end{aligned} \]
where dist \(\left(c_{i}, c_{j}\right)\) refers to the reciprocal distances between the offset positions of the candidate keyphrases \(c_{i}\) and \(c_{j}\) in the document and where \(\operatorname{pos}\left(c_{i}\right)\) represents all the offset positions of the candidate keyphrase \(c_{i}\).
端点是主题不是单词和关键词短语,连线是两个主题之间关键词短语的相似程度。
\[E=\left\{\left(v_{1}, v_{2}\right) \mid \forall v_{1}, v_{2} \in V, v_{1} \neq v_{2}\right\}\]
Our approach to construct the graph differs from TextRank. \(G\) is a complete graph and topics are therefore interconnected. The completeness of the graph has the benefit of providing a more exhaustive view of the relations between topics.
Also, computing weights based on the distances between offset positions bypasses the need for a manually defined parameter, such as the window of words used by state-of-the-art methods (TextRank, SingleRank, etc).
这里也需要去设定超参数,如滑动窗口的长度。
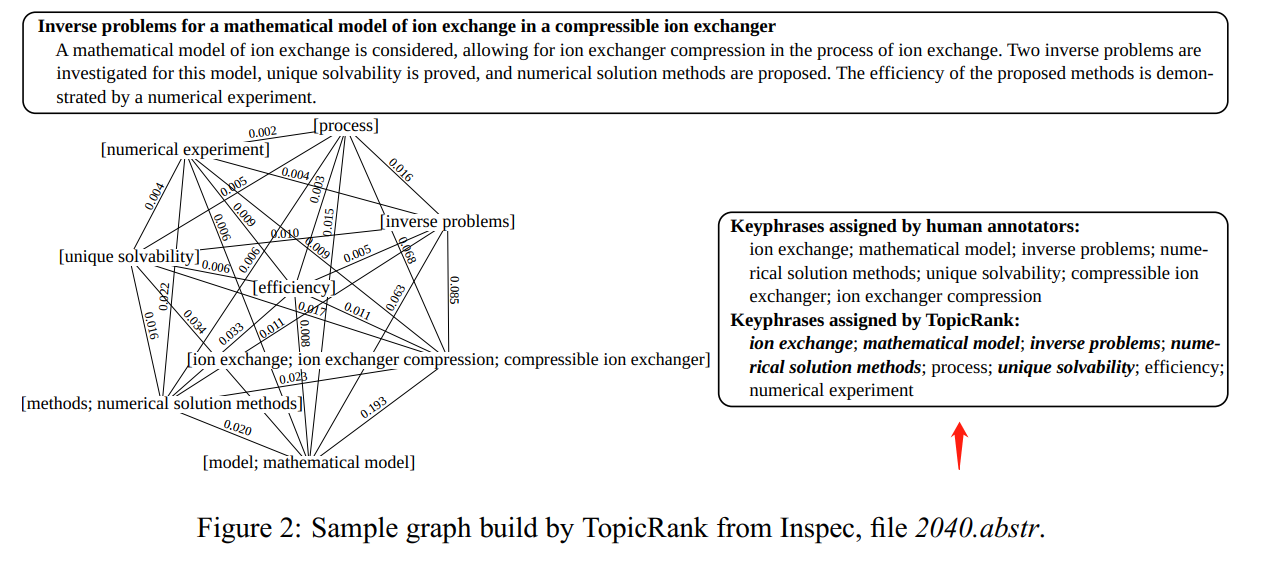
Figure 2: TopicRank 关键词提取的效果,从这个例子可以看出,至少可以部分替代人工去取关键词、语句了。
Figure 2 shows a sample graph built for an abstract from one of our evaluation datasets (Inspec). Vertices are topics, represented as clusters of lexically similar keyphrase candidates, and connected with all the others. In the example, we see the naivety of our clustering approach. Indeed, the clustering succeeds to group “ion exchanger”, “ion exchanger compression” and “compressible ion exchanger”, but the clustering of “methods” with “numerical solution methods” and “model” with “mathematical model” may be ambiguous as “methods” and “model” can be used to refer to other methods or models.
注意顶点上是多个关键词,其实就可以作为正则化,可以作为或条件进行并列。
0.3.2.2 Subject Ranking
Once the graph is created, the graph-based ranking model TextRank, proposed by Mihalcea and Tarau (2004), is used to rank the topics. This model assigns a significance score to topics based on the concept of “voting”: high-scoring topics contribute more to the score of their connected topic \(t_{i}\)
\[ S\left(t_{i}\right)=(1-\lambda)+\lambda \times \sum_{t_{j} \in V_{i}} \frac{w_{j, i} \times S\left(t_{j}\right)}{\sum_{t_{k} \in V_{j}} w_{j, k}} \]
where \(V_{i}\) are the topics voting for \(t_{i}\) and \(\lambda\) is a damping factor generally defined to 0.85 (Brin and Page, 1998).
\(\lambda\) 是正则化参数。
- 这个公式没有完全看懂 这里 i,j,k 分别代表的是? 其实就是一个标准化权重的感觉。
0.3.2.3 Keyphrase Selection
Keyphrase selection is the last step of TopicRank. For each topic, only the most representative keyphrase candidate is selected. This selection avoids redundancy
有 group 的思想,因此减少了冗余。
and leads to a good coverage of the document topics, because extracting \(k\) keyphrases precisely covers \(k\) topics.
一个具体有 N 个主题,那么就是 N 个关键词组,这样简单整洁。
To find the candidate that best represents a topic, we propose three strategies. Assuming that a topic is first introduced by its generic form, the first strategy is to select the keyphrase candidate that appears first in the document. The second strategy assumes that the generic form of a topic is the one that is most frequently used and the third strategy selects the centroid of the cluster. The centroid is the candidate that is the most similar to the other candidates of the cluster.
找最有代表性的,三种策略
- 首次出现的短语
- 最高频的
- 聚类中的质心。
The similarity between two candidates is computed with the stem overlap measure used by the clustering algorithm.
这里的质心其实说到就是聚类算法。
0.4 Experimental Settings
0.4.1 Datasets
四个数据集的说明,可惜没有中文的测试。
To compare the keyphrases extracted by TopicRank against existing methods, we employ four standard evaluation dataset of different languages, document sizes and domains.
The first dataset, formerly used by Hulth (2003), contains 2000 English abstracts of journal papers from the Inspec database. The 2000 abstracts are divided into three sets: a training set, which contains 1000 abstracts, a validation set containing 500 abstracts and a test set containing the 500 remaining abstracts. In our experiments we use the 500 abstracts from the test set. Several reference keyphrase sets are available with this dataset. Just as Hulth (2003), we use the uncontrolled reference, created by professional indexers.
The second dataset was built by \(\mathrm{Kim}\) et al. (2010) for the keyphrase extraction task of the SemEval 2010 evaluation campaign. This dataset is composed of 284 scientific articles (in English) from the ACM Digital Libraries (conference and workshop papers). The 284 documents are divided into three sets: a trial set containing 40 documents, a training set, which contains 144 documents and a test set containing 100 documents. In our experiments we use the 100 documents of the test set. As for the reference keyphrases, we use the combination of author and reader assigned keyphrases provided by Kim et al.(2010).
The third dataset is a French corpus that we created from the French version of WikiNews. It contains 100 news articles published between May 2012 and December 2012 . Each document has been annotated by at least three students. We combined the annotations of each document and removed the lexical redundancies. All of the 100 documents are used in our experiments.
The WikiNews dataset is available for free at the given url: https://github.com/adrien-bougouin/WikinewsKeyphraseCorpus.
The fourth dataset is a French corpus made for the keyphrase extraction task of the DEFT 2012 evaluation campaign (Paroubek et al., 2012 ). It contains 468 scientific articles extracted from Érudit. These documents are used for two tasks of DEFT and are, therefore, divided in two datasets of 244 documents each. In our experiments we use the test set of the second task dataset. It contains 93 documents provided with author keyphrases.
Table 1 gives statistics about the datasets. They are different in terms of document sizes and num- ber of assigned keyphrases. The Inspec and WikiNews datasets have shorter documents (abstract and news articles) compared to SemEval and DEFT that both contain full-text scientific articles. Also, the keyphrases provided with the datasets are not always present in the documents (less than \(5 \%\) of missing keyphrases for Wikinews and about \(20 \%\) of missing keyphrases for the other datasets). This induces a bias in the results. As explained by Hasan and Ng (2010) , some researchers avoid this problem by removing missing keyphrases from the references. In our experiments, missing keyphrases have not been removed. However, we evaluate with stemmed forms of candidates and reference keyphrases to reduce mismatches.
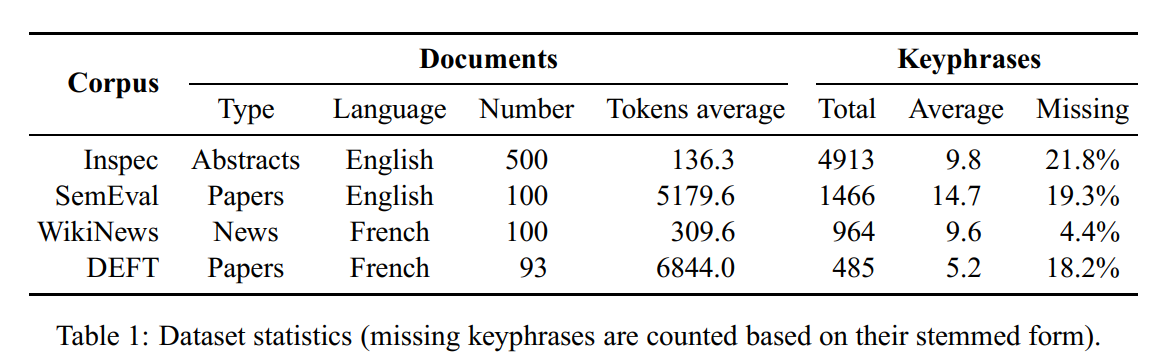
Figure 3: Bougouin, Boudin, and Daille (2013) 测评的四个数据集中文档、短语的说明。
0.4.2 Preprocessing
文本预处理
For each dataset, we apply the following pre processing steps: sentence segmentation, wor tokenization and Part-of-Speech tagging. Fo word tokenization, we use the TreebankWordTokenizer provided by the python Natural Languag ToolKit (Bird et al., 2009) for English and th Bonsai word tokenizer for French. For Part of-Speech tagging, we use the Stanford POS. tagger (Toutanova et al., 2003) for English an MElt (Denis and Sagot, 2009) for French.
The Bonsai word tokenizer is a tool provided with the Bonsai PCFG-LA parser: http://alpage.inria.fr/statgram/frdep/fr_stat_dep_parsing.html.
0.4.3 Baselines
baseline 超参数说明
For comparison purpose, we use three baselines. The first baseline is TF-IDF (Spärck Jones,1972), commonly used because of the difficulty to achieve competitive results against it (Hasan and Ng, 2010). This method relies on a collection of documents and assumes that the \(k\) keyphrase candidates containing words with the highest TF-IDF weights are the keyphrases of the document. As TopicRank aims to be an improvement of the state-of-the-art graph-based methods for keyphrase extraction, the last two baselines are TextRank (Mihalcea and Tarau, 2004) and singleRank (Wan and Xiao, 2008).
In these methods, the graph is undirected, vertices are syntactically filtered words (only nouns and adjectives) and the edges are created based on the cooccurrences of words within a window of 2 for TextRank and 10 for singleRank.
共现程度计算是需要滑动窗口的不可能从整个文档出发(TFIDF就是整个文档)。
As well as their window size, they differ in the weighting of the graph: TextRank has an unweighted graph and singleRank has a graph weighted with the number of co-occurrences between the words. A graph-based ranking model derived from PageRank (Brin and Page, 1998) ranks each vertex and extracts multi-word keyphrases according to the ranked words. In TextRank, the \(k\) -best words are used as keyphrases and the adjacent sequences in the document are collapsed into multi-word keyphrases. Although \(k\) is normally proportional to the number of vertices in the graph, we set it to a constant number, because experiments conducted by Hasan and Ng (2010) show that the optimal value of the ratio depends on the size of the document. In SingleRank, noun phrases extracted with the same method as TopicRank are ranked by a score equal to the sum of their words scores. Then, the \(k\)-best noun phrases are selected as keyphrases.
SingleRank、TextRank 都是用 top-k 的方式提取名词句子
For all the baselines, we consider keyphrase candidates which have the same stemmed form as redundant. Once they are ranked we keep the best candidate and remove the others. This can only affect the results in a positive way, because the evaluation is performed with stemmed forms, which means that removed candidates are considered equal to the retained candidate.
0.4.4 Evaluation Measures
The performances of TopicRank and the baselines are evaluated in terms of precision, recall and f-score (f1-measure) when a maximum of 10 keyphrases are extracted \((k=10)\). As said before, the candidate and reference keyphrases are stemmed to reduce the number of mismatches.
0.5 Results
To validate our approach, we designed three experiments. The first experiment compares TopicRank3 to the baselines,4
复现地址见 https://github.com/adrien-bougouin/KeyBench/tree/ijcnlp_2013
the second experiment individually evaluates the modifications of TopicRank compared to singleRank5 and the last experiment compares the keyphrase selection strategies. To show that the clusters are well ranked, we also present the results that could be achieved with a “perfect” keyphrase selection strategy.
TopicRank 并没有在所有的任务上胜出。
0.5.1 Table 2
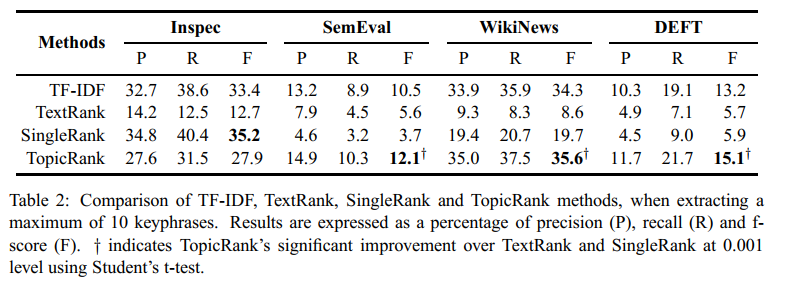
Figure 4: TopicRank 和几个 baseline 的比较情况。
Table 2 shows the results of TopicRank and the three baselines. Overall, our method outperforms TextRank, SingleRank and TF-IDF.
- 需要好好对比下对应的部分。
除了在 Inspec 数据集上,其他数据集上 F1 都表现得更好。
The results of TopicRank and the baselines are lower on SemEval and DEFT (less than \(16 \%\) of f-score), so we deduce that it is more difficult to treat long documents than short ones.
TopicRank 和其他 baselines 在 SemEval 和 DEFT 上的 F1 得分都很低,这说明长文本难以做文本摘要,但是短文本表现不错。
On Inspec, TopicRank fails to do better than all the baselines, but on SemEval, WikiNews and DEFT, it performs better than TFIDF and significantly outperforms TextRank and singleRank.
Also, we observe a gap between TFIDF’s and the two graph-based baselines results.
TF-IDF 得分一直不错。
Although TopicRank is a graph-based method, it overcomes this gap by almost tripling the f-score of both TextRank and singleRank.
TopicRank 远胜于 其他 *Rank 算法。
0.5.2 Table 3
Table 3 shows the individual modifications of TopicRank compared to SingleRank. We evaluate SingleRank when vertices are keyphrase candidates (+phrases), vertices are topics (+ topics) and when TopicRank’s graph construction is used with word vertices (+$ complete). Using keyphrase candidates as vertices significantly improves SingleRank on SemEval, WikiNews and DEFT.
所以用 keyphrase 这项技术产生了提升。
同时对比了词、短语作为顶点,在 SingleRank 和 TopicRank 上的效果对比。
On Inspec, it induces a considerable loss of performance caused by an important deficit of connections that leads to connected components, as shown in Figure \(3 .\)
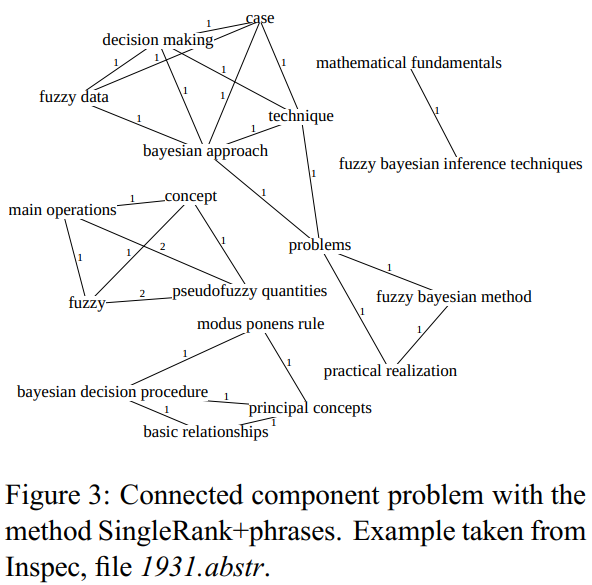
Figure 5: 如果使用短语,会发生 n-grams 的问题,减少了共现程度。
When we look at the distribution of “fuzzy” into the graph, we can see that it is scattered among the connected components and, therefore, increases the difficulty to select “fuzzy Bayesian inference techniques” as a keyphrase (according to the reference). The other datasets contain longer documents, which may dampen this problem. Overall, using topics as vertices performs better than using keyphrase candidates. Using topics significantly outperforms singleRank on SemEval, WikiNews and DEFT. As for the new graph construction, singleRank is improved on Inspec, SemEval and WikiNews. Results on DEFT are lower than singleRank, but still competitive. Although the improvements are not significant, the competitive results point out that the new graph construction can be used instead of the former method, which requires to manually define a window of words. Experiments show that the three contributions are improvements and TopicRank benefits from each of them.
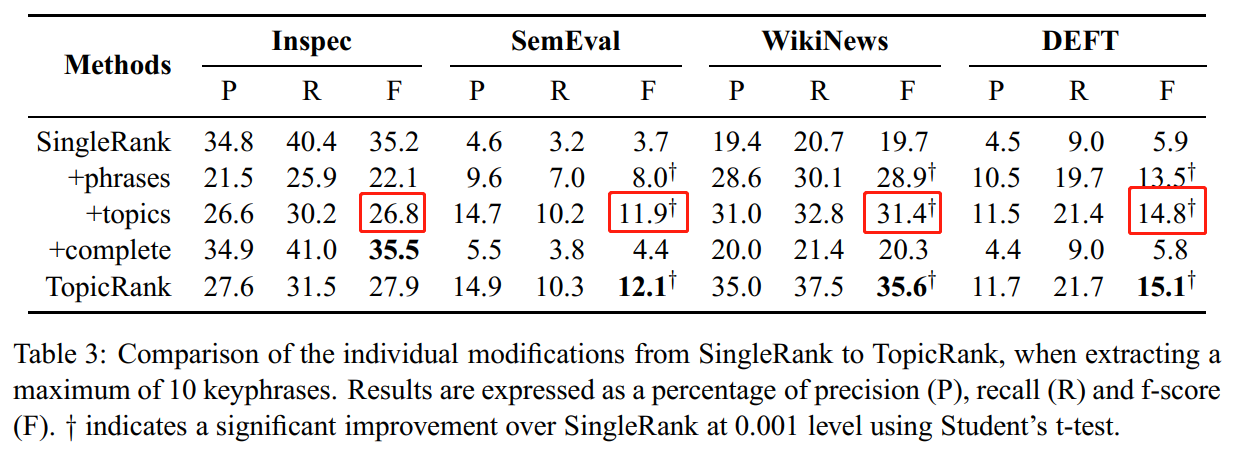
Figure 6: TopicRank 是用 Topic 进行共现处理,因此避免了 n-grams 的问题,增加了共现程度,是的 SingleRank 经过这个改进变得更好了。
0.5.3 Table 4
Table 4 shows the results of TopicRank when selecting either the first appearing candidate, the most frequent one or the centroid of each cluster. Selecting the first appearing keyphrase candidate the best strategy of the three. It significantly outperforms the frequency and the centroid strategies on SemEval, WikiNews and DEFT. On SemEval and DEFT, we observe a huge gap between the results of the first position strategy and the others. The two datasets are composed of scientific articles where the full form of the main topics are often introduced at the beginning and then, conveyed by abbreviations or inherent concepts (e.g. the file \(C-17 . t x t\) from SemEval contains packet-switched network as a keyphrase where packet is more utilized in the content). These are usually more similar to the generic form and/or more frequent, which explains the observed gap.
top-n 的策略中,为什么第一个效果最好呢? 因为科学文章中,通常第一个词表示短语的开始,如“packet-switched network”中的“packet”这解释了为什么这样的策略更好。
To observe the ranking efficiency of TopicRank, we also evaluate it without taking the keyphrase selection strategy into account. To do so, we extract the top-ranked clusters and mark the reference keyphrases into them. We deduce the upper bound results of our method by computing the precision, recall and f-score where the number of correct matches is equal to the number of clusters containing at least one reference keyphrase. The upper bound results show that our method could possibly perform better than all the baselines for the four datasets. Even on Inspec, the loss of performance can be bypassed by a more efficient keyphrase selection strategy.
- 如何理解这里 upper bound 的实验设计
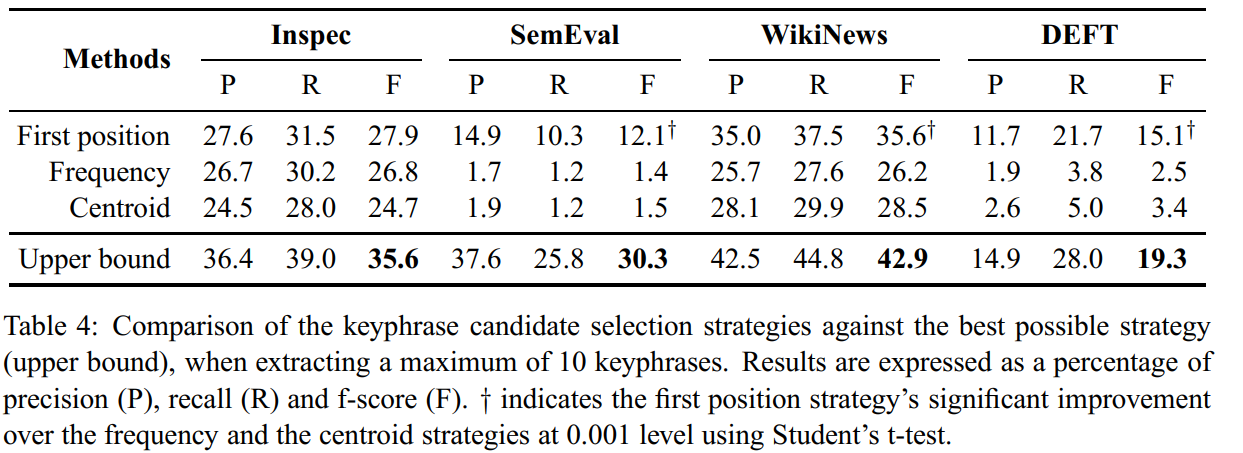
Figure 7: Upper Bound 效果更好。
0.6 Conclusion and Future Work
Our approach offers several advantages over existing graph-based keyphrase extraction methods. First, as redundant keyphrase candidates are clustered, extracted keyphrases cover the main topics of the document better. The use of a complete graph also captures the relations between topics without any manually defined parameters and induces better or similar performances than the state-of-the-art connection method that uses a co-occurrence windows.
“组”思想减少了 n-gram 的问题。
Bougouin, Adrien, Florian Boudin, and Béatrice Daille. 2013. “TopicRank: Graph-Based Topic Ranking for Keyphrase Extraction.” In International Joint Conference on Natural Language Processing (Ijcnlp), 543–51.
The value of \(25 \%\) has been defined empirically.↩
We chose to use stems because of the availability of stemmers for various languages, but using lemmas is another possibility that could probably work better.↩
Results reported for TopicRank are obtained with the first position selection strategy.↩
TopicRank and the baselines implementations can be found at the given url: https://github.com/adrien-bougouin/KeyBench/tree/ijcnlp_2013.↩
The second experiment is performed with SingleRank instead of TextRank, because SingleRank also uses a graph with weighted edges and is, therefore, closer to TopicRank.↩