customer_segmentation
可视化聚类个数的效率
参考lazappi
suppressMessages(library(tidyverse))
library(data.table)
##
## Attaching package: 'data.table'
## The following objects are masked from 'package:dplyr':
##
## between, first, last
## The following object is masked from 'package:purrr':
##
## transpose
label <- fread("data/clustree/datamart_rfmt_label.csv",drop = 1,header = T)
data <- fread("data/clustree/datamart_rfmt_normalized.csv",drop = 1)
label <-
label %>%
set_names(
paste0('K',1:10)
)
pc <-
data %>%
select(Recency:Tenure) %>%
prcomp() %>%
predict() %>%
as.data.frame()
data_cb <- bind_cols(data,label,pc)
library(clustree)
## Loading required package: ggraph
overlay_list <- clustree_overlay(data_cb, prefix = "K", x_value = "PC1",
y_value = "PC2", plot_sides = TRUE)
names(overlay_list)
## [1] "overlay" "x_side" "y_side"
#> [1] "overlay" "x_side" "y_side"
overlay_list$x_side
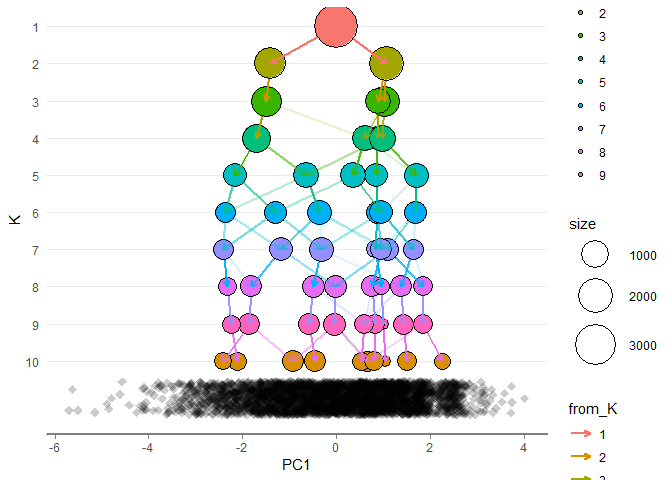
- 其实这里会发现,3个和4个的分类模糊不清,因此聚类确定在4个以下就差不多了。
- 并且,中间有一束,非常集中,大多数分类都在那个位置重叠,会导致聚类效果很差。
并且这里的 K 序列实际上可以换成不同的方法比较,比如
- K1 代表 简单处理的结果
- K2 代表 KMEANS
- K3 代表 t-SNE 做的处理
最后比较几种方法的差异,在实际过程中,应该差异不大,因此可以作为拒绝使用复杂模型的证据。 并且,这也可以说,用户分群,应该从简单方法入手,只要复杂模型没有提供更高的效率,可以使用简单模型。 越简单的模型,稳定性越高。