learn_nlp
NLP中文小例子
Jiaxiang Li 2019-04-22
数据和代码参考 github, 代码进行了 Tidyverse 的风格修改,参考 Github Pages。
之所以增加中文小例子,是因为大部分 NLP 小例子都是英文文本,对于业务的借鉴意义比较小。
library(lime)
library(text2vec)
library(data.table)
library(xgboost)
library(jiebaR)
library(tidyverse)
library(magrittr)
library(caret)
library(knitr)
词向量处理
good_sentences <- fread(
"datasets/good_comment.csv",
stringsAsFactors = FALSE,
encoding = "UTF-8"
)
bad_sentences <- fread(
"datasets/bad_comment.csv",
stringsAsFactors = FALSE,
encoding = "UTF-8"
)
good_sentences %>% head %>% kable()
| id | area | com_client | comment | goods_name | score | times | user_grade | user_id |
|---|---|---|---|---|---|---|---|---|
| 0 | 宁夏 | 来自京东Android客户端 | 京东的物流是没得说了,很快。这次买酒水类,包装很仔细,没有出现意外。酒到手了,绝对是正品。感觉很不错哟! | 霞多丽白 | grade-star g-star5 | 2016-06-19 11:29 | 金牌会员 | 大***抱 |
| 1 | 天津 | 来自京东iPhone客户端 | 活动买的,低档葡萄酒认准澳洲就对了 | 桑格利亚 | grade-star g-star5 | 2016-08-04 20:19 | 金牌会员 | j***v |
| 2 | 河南 | 好吃,但是价格也不便宜的啊 | 西拉-红 | grade-star g-star5 | 2016-09-05 22:37 | 钻石会员 | 芬***神 | |
| 3 | 北京 | 到货很快,第二天就到了,东西包装细致,感觉很不错!只是口感不是我喜欢的! | 西拉-红 | grade-star g-star5 | 2016-08-30 22:50 | 金牌会员 | c***9 | |
| 4 | 江苏 | 来自京东iPhone客户端 | 不错,价格实惠,值得购买 | 梅洛-红 | grade-star g-star4 | 2016-09-01 20:03 | 钻石会员 | t***k |
| 5 | 来自京东Android客户端 | 不是干红 。。买错了 | 西拉-红 | grade-star g-star4 | 2016-09-02 10:45 | 铜牌会员 | 大***尚 |
bad_sentences %>% head %>% kable()
| id | area | com_client | comment | goods_name | score | times | user_grade | user_id |
|---|---|---|---|---|---|---|---|---|
| 0 | 广东 | 来自京东iPhone客户端 | 假酒。便宜没好货 喝完头超疼 | 梅洛-红 | grade-star g-star1 | 2016-08-18 16:51 | 铜牌会员 | j***6 |
| 1 | 来自京东iPhone客户端 | 红酒最基本的木塞都没有 真差这酒 | 梅洛-红 | grade-star g-star1 | 2016-09-03 14:28 | 银牌会员 | j***p | |
| 2 | 广东 | 来自京东iPhone客户端 | 酒不杂样 | 西拉-红 | grade-star g-star1 | 2016-08-23 16:45 | 金牌会员 | j***m |
| 3 | 来自京东iPhone客户端 | 居然写错收件人名称,幸亏别人拿回家又送回来! | 梅洛-红 | grade-star g-star1 | 2016-09-01 18:39 | 银牌会员 | R***S | |
| 4 | 来自京东iPhone客户端 | 瓶盖破损了,两瓶都这样 | 西拉-红 | grade-star g-star1 | 2016-09-03 14:18 | 铜牌会员 | j***h | |
| 5 | 广东 | 来自京东iPhone客户端 | 图片上是14年的:送过来是15年 | 西拉-红 | grade-star g-star1 | 2016-09-02 13:01 | 钻石会员 | j***2 |
增加 y 变量
good_sentences %<>%
mutate(label = 1)
bad_sentences %<>%
mutate(label = 0)
all_sentences <- bind_rows(good_sentences, bad_sentences)
all_sentences %>% dim
## [1] 2014 10
good_sentences %>% dim
## [1] 1005 10
bad_sentences %>% dim
## [1] 1009 10
cutter <- worker(
type = "mix",
bylines = TRUE,
stop_word = "datasets/stopwords.txt"
)
read_lines("datasets/stopwords.txt") %>%
str_subset('的')
## [1] "似的" "别的" "总的来看" "总的来说" "总的说来" "是的"
## [7] "有的" "的" "的确" "的话" "般的"
分词过程中需要导出新增词,这里参考 github
词向量分测试组和对照组参考 github,我认为不是很好的方法。 在全集合词向量构建后,再进行测试组和对照组的切分。 而非先分对照组和测试组再进行词向量构建。
article_words <- sapply(all_sentences$comment, function(x) cutter <= x)
article_words %>% length
## [1] 2014
article_words %>% class
## [1] "list"
it_token <- itoken(
article_words,
ids = rownames(all_sentences),
progressbar = TRUE
)
vocab <- create_vocabulary(it_token)
##
|
|======= | 10%
|
|============= | 20%
|
|==================== | 30%
|
|========================== | 40%
|
|================================= | 50%
|
|======================================= | 60%
|
|============================================== | 70%
|
|==================================================== | 80%
|
|=========================================================== | 90%
|
|=================================================================| 100%
bigram_vectorizer <- vocab_vectorizer(vocab)
dtm_token <- create_dtm(it_token, bigram_vectorizer)
##
|
|======= | 10%
|
|============= | 20%
|
|==================== | 30%
|
|========================== | 40%
|
|================================= | 50%
|
|======================================= | 60%
|
|============================================== | 70%
|
|==================================================== | 80%
|
|=========================================================== | 90%
|
|=================================================================| 100%
dtm_token %>% dim
## [1] 2014 1317
set.seed(42)
idx <- createDataPartition(all_sentences$label, p = 0.8, list = FALSE, times = 1) %>% as.vector()
注意这里createDataPartition的格式非向量。
dtrain <- dtm_token[ idx,] %>% xgb.DMatrix(label = all_sentences[ idx,]$label)
dtest <- dtm_token[-idx,] %>% xgb.DMatrix(label = all_sentences[-idx,]$label)
watchlist <- list(train = dtrain, eval = dtest)
模型训练
注意这个地方字典设置要同一组,否则 train 和 test 变量会不一致。
xgb_model <- xgb.train(list(max_depth = 4,
eta = 0.1,
objective = "binary:logistic",
eval_metric = "error", nthread = 1),
data = dtrain,watchlist = watchlist,
nrounds = 100)
## [1] train-error:0.282258 eval-error:0.273632
## [2] train-error:0.216501 eval-error:0.223881
## [3] train-error:0.216501 eval-error:0.223881
## [4] train-error:0.213399 eval-error:0.218905
## [5] train-error:0.160670 eval-error:0.146766
## [6] train-error:0.154466 eval-error:0.144279
## [7] train-error:0.153846 eval-error:0.149254
## [8] train-error:0.145161 eval-error:0.139303
## [9] train-error:0.153846 eval-error:0.144279
## [10] train-error:0.108561 eval-error:0.094527
## [11] train-error:0.107320 eval-error:0.099502
## [12] train-error:0.107320 eval-error:0.099502
## [13] train-error:0.103598 eval-error:0.099502
## [14] train-error:0.104218 eval-error:0.094527
## [15] train-error:0.104839 eval-error:0.094527
## [16] train-error:0.103598 eval-error:0.099502
## [17] train-error:0.104839 eval-error:0.099502
## [18] train-error:0.104218 eval-error:0.099502
## [19] train-error:0.105459 eval-error:0.094527
## [20] train-error:0.104839 eval-error:0.094527
## [21] train-error:0.101737 eval-error:0.094527
## [22] train-error:0.104218 eval-error:0.094527
## [23] train-error:0.102357 eval-error:0.094527
## [24] train-error:0.102357 eval-error:0.094527
## [25] train-error:0.101737 eval-error:0.094527
## [26] train-error:0.096154 eval-error:0.094527
## [27] train-error:0.101737 eval-error:0.094527
## [28] train-error:0.093672 eval-error:0.092040
## [29] train-error:0.093052 eval-error:0.092040
## [30] train-error:0.093052 eval-error:0.092040
## [31] train-error:0.093052 eval-error:0.092040
## [32] train-error:0.083127 eval-error:0.092040
## [33] train-error:0.082506 eval-error:0.092040
## [34] train-error:0.082506 eval-error:0.092040
## [35] train-error:0.081886 eval-error:0.092040
## [36] train-error:0.082506 eval-error:0.092040
## [37] train-error:0.082506 eval-error:0.092040
## [38] train-error:0.081886 eval-error:0.092040
## [39] train-error:0.081886 eval-error:0.092040
## [40] train-error:0.081886 eval-error:0.092040
## [41] train-error:0.081886 eval-error:0.092040
## [42] train-error:0.081886 eval-error:0.092040
## [43] train-error:0.081886 eval-error:0.092040
## [44] train-error:0.081886 eval-error:0.092040
## [45] train-error:0.081886 eval-error:0.092040
## [46] train-error:0.081886 eval-error:0.092040
## [47] train-error:0.080645 eval-error:0.092040
## [48] train-error:0.080025 eval-error:0.092040
## [49] train-error:0.080025 eval-error:0.089552
## [50] train-error:0.078164 eval-error:0.092040
## [51] train-error:0.078164 eval-error:0.092040
## [52] train-error:0.077543 eval-error:0.092040
## [53] train-error:0.077543 eval-error:0.092040
## [54] train-error:0.077543 eval-error:0.092040
## [55] train-error:0.077543 eval-error:0.092040
## [56] train-error:0.077543 eval-error:0.092040
## [57] train-error:0.077543 eval-error:0.089552
## [58] train-error:0.076923 eval-error:0.089552
## [59] train-error:0.076923 eval-error:0.089552
## [60] train-error:0.076923 eval-error:0.089552
## [61] train-error:0.076923 eval-error:0.089552
## [62] train-error:0.076923 eval-error:0.089552
## [63] train-error:0.076303 eval-error:0.089552
## [64] train-error:0.076303 eval-error:0.089552
## [65] train-error:0.071960 eval-error:0.087065
## [66] train-error:0.075682 eval-error:0.089552
## [67] train-error:0.071960 eval-error:0.087065
## [68] train-error:0.075682 eval-error:0.089552
## [69] train-error:0.075682 eval-error:0.089552
## [70] train-error:0.074442 eval-error:0.089552
## [71] train-error:0.070099 eval-error:0.087065
## [72] train-error:0.069479 eval-error:0.087065
## [73] train-error:0.066998 eval-error:0.087065
## [74] train-error:0.066998 eval-error:0.087065
## [75] train-error:0.066998 eval-error:0.087065
## [76] train-error:0.066998 eval-error:0.087065
## [77] train-error:0.066998 eval-error:0.087065
## [78] train-error:0.066998 eval-error:0.087065
## [79] train-error:0.066998 eval-error:0.087065
## [80] train-error:0.066998 eval-error:0.087065
## [81] train-error:0.066998 eval-error:0.087065
## [82] train-error:0.066998 eval-error:0.087065
## [83] train-error:0.066998 eval-error:0.087065
## [84] train-error:0.066998 eval-error:0.089552
## [85] train-error:0.063896 eval-error:0.089552
## [86] train-error:0.063896 eval-error:0.089552
## [87] train-error:0.063896 eval-error:0.089552
## [88] train-error:0.063896 eval-error:0.089552
## [89] train-error:0.063896 eval-error:0.089552
## [90] train-error:0.063896 eval-error:0.089552
## [91] train-error:0.063275 eval-error:0.087065
## [92] train-error:0.061414 eval-error:0.082090
## [93] train-error:0.062035 eval-error:0.084577
## [94] train-error:0.060174 eval-error:0.079602
## [95] train-error:0.060174 eval-error:0.079602
## [96] train-error:0.060174 eval-error:0.077114
## [97] train-error:0.060174 eval-error:0.077114
## [98] train-error:0.060174 eval-error:0.077114
## [99] train-error:0.059553 eval-error:0.074627
## [100] train-error:0.059553 eval-error:0.074627
建立一个 Xgboost 模型。
pred <- predict(xgb_model, dtest)
confusionMatrix(as.factor(all_sentences[-idx,]$label),
as.factor(round(pred, digits = 0)))
## Confusion Matrix and Statistics
##
## Reference
## Prediction 0 1
## 0 191 26
## 1 4 181
##
## Accuracy : 0.9254
## 95% CI : (0.8952, 0.9491)
## No Information Rate : 0.5149
## P-Value [Acc > NIR] : < 2.2e-16
##
## Kappa : 0.8511
## Mcnemar's Test P-Value : 0.000126
##
## Sensitivity : 0.9795
## Specificity : 0.8744
## Pos Pred Value : 0.8802
## Neg Pred Value : 0.9784
## Prevalence : 0.4851
## Detection Rate : 0.4751
## Detection Prevalence : 0.5398
## Balanced Accuracy : 0.9269
##
## 'Positive' Class : 0
##
变量重要性
xgb.importance(model= xgb_model) %>%
mutate_if(is.double, ~round(.,3)) %>%
kable()
| Feature | Gain | Cover | Frequency |
|---|---|---|---|
| 不错 | 0.184 | 0.091 | 0.058 |
| 性价比 | 0.099 | 0.063 | 0.045 |
| 长城 | 0.075 | 0.063 | 0.052 |
| 以后 | 0.057 | 0.034 | 0.023 |
| 没有 | 0.054 | 0.037 | 0.025 |
| 感觉 | 0.050 | 0.036 | 0.021 |
| 买 | 0.048 | 0.021 | 0.021 |
| 不像 | 0.043 | 0.028 | 0.027 |
| 真心 | 0.042 | 0.022 | 0.016 |
| 希望 | 0.034 | 0.034 | 0.027 |
| Hhhhhhhhhhhhhhhhhhh | 0.030 | 0.035 | 0.031 |
| 好好 | 0.027 | 0.036 | 0.031 |
| Hhhhhhhhhhhhhhh | 0.026 | 0.036 | 0.031 |
| 点 | 0.024 | 0.027 | 0.019 |
| 一般般 | 0.019 | 0.037 | 0.039 |
| 直接 | 0.018 | 0.023 | 0.021 |
| 难喝 | 0.018 | 0.037 | 0.033 |
| 知道 | 0.018 | 0.033 | 0.029 |
| 差 | 0.014 | 0.034 | 0.031 |
| 喜欢 | 0.014 | 0.011 | 0.029 |
| 酒 | 0.009 | 0.008 | 0.021 |
| 喝 | 0.009 | 0.004 | 0.037 |
| 电话 | 0.008 | 0.022 | 0.023 |
| 酒精 | 0.008 | 0.021 | 0.021 |
| 烂 | 0.007 | 0.017 | 0.016 |
| 货 | 0.007 | 0.022 | 0.023 |
| 一直 | 0.006 | 0.014 | 0.023 |
| 不要 | 0.005 | 0.014 | 0.016 |
| 垃圾 | 0.005 | 0.016 | 0.016 |
| 假酒 | 0.005 | 0.016 | 0.016 |
| 上当 | 0.004 | 0.007 | 0.006 |
| 木塞 | 0.004 | 0.011 | 0.012 |
| 京东 | 0.004 | 0.008 | 0.047 |
| 瓶 | 0.003 | 0.003 | 0.006 |
| 包装 | 0.003 | 0.007 | 0.008 |
| 送 | 0.003 | 0.008 | 0.008 |
| 超 | 0.002 | 0.008 | 0.008 |
| 差评 | 0.002 | 0.009 | 0.010 |
| 东西 | 0.002 | 0.007 | 0.012 |
| 有点 | 0.001 | 0.007 | 0.008 |
| 承认 | 0.001 | 0.001 | 0.002 |
| 问题 | 0.001 | 0.005 | 0.006 |
| 红酒 | 0.001 | 0.000 | 0.004 |
| 味 | 0.001 | 0.004 | 0.004 |
| 购买 | 0.001 | 0.003 | 0.004 |
| 不送 | 0.001 | 0.003 | 0.004 |
| 半干白 | 0.001 | 0.000 | 0.002 |
| 信赖 | 0.001 | 0.003 | 0.004 |
| 活动 | 0.001 | 0.003 | 0.004 |
| 假 | 0.001 | 0.003 | 0.004 |
| 年 | 0.000 | 0.002 | 0.002 |
| 质量 | 0.000 | 0.002 | 0.002 |
| 牌子 | 0.000 | 0.002 | 0.002 |
| 很快 | 0.000 | 0.002 | 0.002 |
| 送货 | 0.000 | 0.001 | 0.004 |
| 瓶塞 | 0.000 | 0.000 | 0.002 |
LIME
get_matrix <- function(x){
article_words <- sapply(x, function(x) cutter <= x)
it_token <- itoken(
article_words,
progressbar = TRUE
)
dtm_token <- create_dtm(it_token, bigram_vectorizer)
dpred <- xgb.DMatrix(dtm_token)
return(dpred)
}
explainer <- lime(unlist(all_sentences$comment),
xgb_model,
preprocess = get_matrix)
Error in UseMethod("lime", x) :
no applicable method for 'lime' applied to an object of class "list"
因此加入
unlist
Error: Response is constant across permutations. Please check your model
这个报错,主要是跟测试的字段有关,见下面的例子,类似于AB Test。
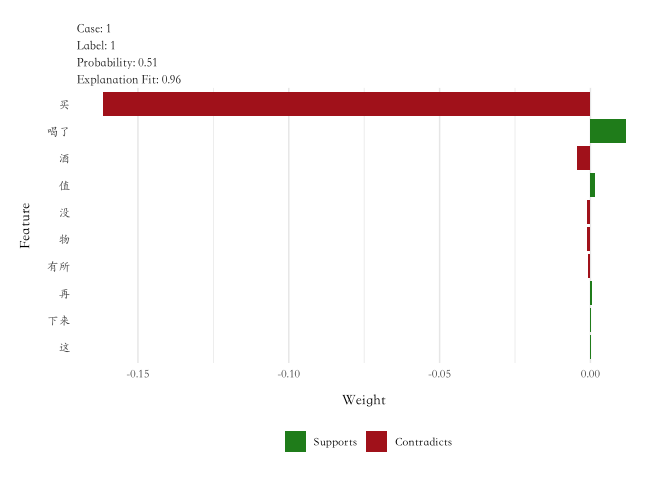
test_comment_1 <- "卧槽,这酒也太好喝了,简直没的说,绝对的物有所值,下来再买"
explanations <- lime::explain(test_comment_1,explainer,n_labels = 1,n_features = 10)
explanations %>% plot_features +
theme(text = element_text(family = 'STKaiti'))
# 这里会被 mask
# https://github.com/thomasp85/lime/issues/48
# 这里设置字体,否则 Mac 会出乱码
# results='hide'
# 保证数据中的 messge 不出现
test_comment_2 <- "红红火火"
safely(lime::explain)(test_comment_2,explainer,n_labels = 1,n_features = 5)
已经也算解决了 Github Issue 151
plot_text_explanations(explanations)

这里并没有标记红和绿,应该是中文的问题。