PyTorch 学习笔记
2020-03-03
- 使用 RMarkdown 的
child参数,进行文档拼接。 - 这样拼接以后的笔记方便复习。
- 相关问题提交到 GitHub
Elezi (2019) 的内容有三个两点
- 学习 Facebook PyTorch 的框架
- 理解 Convolution and Padding
- 理解 Transfer Learning
参考 https://pytorch.org/get-started/locally/
conda install pytorch-cpu torchvision-cpu -c pytorch # Windows 7
conda install pytorch torchvision -c pytorch # MacOS1 理解 Pytorch tensor
The blackcellmagic extension is already loaded. To reload it, use:
%reload_ext blackcellmagic# Create random tensor of size 3 by 3
your_first_tensor = torch.rand(3, 3)
# Calculate the shape of the tensor
tensor_size = your_first_tensor.shape
# Print the values of the tensor and its shape
print(your_first_tensor)
print(tensor_size)tensor([[0.0249, 0.3875, 0.9637],
[0.6190, 0.8936, 0.4906],
[0.6484, 0.1036, 0.5873]])
torch.Size([3, 3])# Create a matrix of ones with shape 3 by 3
tensor_of_ones = torch.ones(3, 3)
print(tensor_of_ones)
# Create an identity matrix with shape 3 by 3
identity_tensor = torch.eye(3)
print(identity_tensor)
# Element-wise multiply tensor_of_ones with identity_tensor
matrices_multiplied = torch.matmul(tensor_of_ones, identity_tensor)
print(matrices_multiplied)
# Element-wise multiply tensor_of_ones with identity_tensor
element_multiplication = tensor_of_ones * identity_tensor
print(element_multiplication)tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
tensor([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
tensor([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])可以验证一些线性代数的想法。
# Initialize tensors x, y and z
x = torch.rand(1000, 1000)
y = torch.rand(1000, 1000)
z = torch.rand(1000, 1000)
print(x.shape, y.shape, z.shape)
# Multiply x with y
q = torch.matmul(x, y)
print(q.shape)
# Multiply elementwise z with q
f = z * q
mean_f = torch.mean(f)
print(mean_f) # shape(1,1)torch.Size([1000, 1000]) torch.Size([1000, 1000]) torch.Size([1000, 1000])
torch.Size([1000, 1000])
tensor(125.0998)torch.Tensortorch.mean 把一个二维变量降维为一个常数。
… how to compute derivatives! While PyTorch computes derivatives for you, mastering them will make you a much better deep learning practitioner and that knowledge will guide you in training neural networks better.
理解如何在神经网络中求导,可以方便我们更好实践。
# Initialize x, y and z to values 4, -3 and 5
x = torch.tensor(4., requires_grad = True)
y = torch.tensor(-3.,requires_grad = True)
z = torch.tensor(5., requires_grad = True)
# Set q to sum of x and y, set f to product of q with z
q = x + y
f = z * q
# Compute the derivatives
f.backward()
# Print the gradients
print("Gradient of x is: " + str(x.grad))
print("Gradient of y is: " + str(y.grad))
print("Gradient of z is: " + str(z.grad))这个梯度下降过程实现的不错!
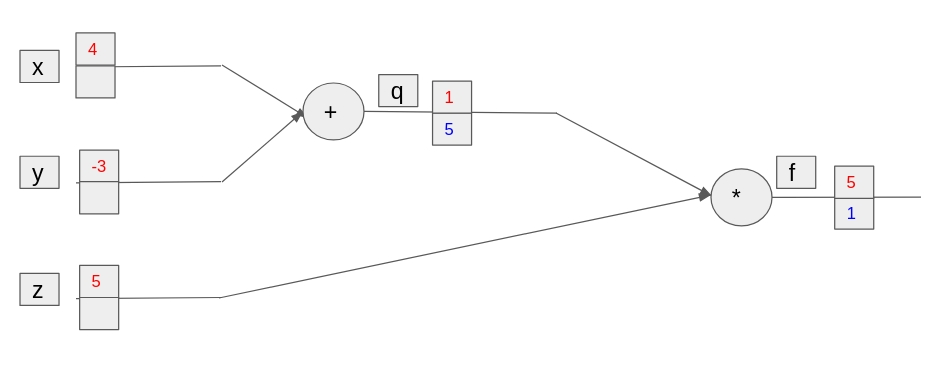
梯度下降
# Initialize the weights of the neural network
weight_1 = torch.rand(784, 200)
weight_2 = torch.rand(200, 10)
# Multiply input_layer with weight_1
hidden_1 = torch.matmul(input_layer, weight_1)
# Multiply hidden_1 with weight_2
output_layer = torch.matmul(hidden_1, weight_2)
print(output_layer)tensor([[18938.6172, 18050.3359, 20434.3965, 19943.2285, 20502.7695, 19317.7422,
19452.3828, 19648.2441, 18432.9512, 19240.4980]])这是直接的 MLP 算法。
提前训练好的。
For the most part, neural networks are just matrix (tensor) multiplication. This is the reason why we have put so much emphasis on matrices and tensors!
大多时候,神经网络仅仅是涉及矩阵相乘,这是一个非常有经验的说法。 学习下 class 建立函数,为后续写包有帮助。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# Instantiate all 2 linear layers
self.fc1 = nn.Linear(784, 200)
self.fc2 = nn.Linear(200, 10)
def forward(self, x):
# Use the instantiated layers and return x
x = self.fc1(x)
x = self.fc2(x)
return x这么看,其实 forward pyTorch 挺清晰的。
后期会发现,__init__ 定义的越 sequence,forward 会越简单。
2 MLP 搭建
The blackcellmagic extension is already loaded. To reload it, use:
%reload_ext blackcellmagic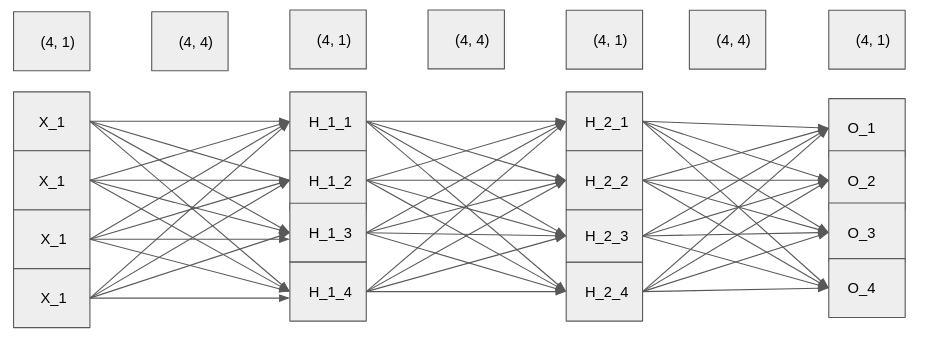
MLP 中矩阵相乘具体表现。
2.1 实现 MLP
input_layer = torch.rand(1,4)
weight_1 = torch.rand(4,4)
weight_2 = torch.rand(4,4)
weight_3 = torch.rand(4,4)# Calculate the first and second hidden layer
hidden_1 = torch.matmul(input_layer, weight_1)
hidden_2 = torch.matmul(hidden_1, weight_2)
output = torch.matmul(hidden_2, weight_3)
# Calculate the output
print(output)
# Calculate weight_composed_1 and weight
weight_composed_1 = torch.matmul(weight_1, weight_2)
weight = torch.matmul(weight_composed_1, weight_3)
# Multiply input_layer with weight
print(torch.matmul(input_layer, weight))tensor([[4.1747, 2.9866, 4.6681, 5.9294]])
tensor([[4.1747, 2.9866, 4.6681, 5.9294]])这正好说明了 linear 的变换没有什么用,一定要用非线性函数 ReLu等。
\[\begin{array}{c}{X W_{1}=H_{1}} \\ {H_{1} W_{1}=H_{2}} \\ {H_{2} W_{2}=H_{3}} \\ {H_{3} W_{3}=O}\end{array}\]
因此
\[XW_1W_2W_3 = O\]
# Apply non-linearity on hidden_1 and hidden_2
hidden_1_activated = relu(torch.matmul(input_layer, weight_1))
hidden_2_activated = relu(torch.matmul(hidden_1_activated, weight_2))
print(torch.matmul(hidden_2_activated, weight_3))
# Apply non-linearity in the product of first two weights.
weight_composed_1_activated = relu(torch.matmul(weight_1, weight_2))
# Multiply `weight_composed_1_activated` with `weight_3
weight = torch.matmul(weight_composed_1_activated, weight_composed_1_activated)
# Multiply input_layer with weight
print(torch.matmul(input_layer, weight))tensor([[4.1747, 2.9866, 4.6681, 5.9294]])
tensor([[9.7038, 9.1091, 8.5771, 4.8548]])每一步进行 relu 都会产生不一样的效果。
2.2 计算损失函数
# Initialize the scores and ground truth
logits = torch.tensor([[-1.2, 0.12, 4.8]])
ground_truth = torch.tensor([2])tensor([[-1.2000, 0.1200, 4.8000]])torch.Size([1])class = [0,1,2]
# Instantiate cross entropy loss
criterion = nn.CrossEntropyLoss()
# Compute and print the loss
loss = criterion(logits, ground_truth)
print(loss)tensor(0.0117)Being proficient in understanding and calculating loss functions is a very important skill in deep learning.
损失函数的定义可以帮助我们理解深度学习。
# Initialize logits and ground truth
logits = torch.rand(1, 1000)
ground_truth = torch.tensor([111])
# Instantiate cross-entropy loss
criterion = nn.CrossEntropyLoss()
# Calculate and print the loss
loss = criterion(logits, ground_truth)
print(loss)tensor(7.1459)6.907755278982137The score is close to -ln(1/1000) = 6.9. This is not surprising, considering that scores were random and close to each other, so the probability for each class was approximately the same (1/1000) = 0.001.
随机选择一个分类进行预测,那么概率机会为1/1000左右。
使用 MNIST 进行 MLP 搭建。
# Transform the data to torch tensors and normalize it
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307), ((0.3081)))]
)
# Prepare the datasets
trainset = torchvision.datasets.MNIST(
"mnist", train=True, download=True, transform=transform
)
testset = torchvision.datasets.MNIST(
"mnist", train=False, download=True, transform=transform
)
# Prepare the dataloaders
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=32, shuffle=True, num_workers=0
)
testloader = torch.utils.data.DataLoader(
testset, batch_size=32, shuffle=False, num_workers=0
)0it [00:00, ?it/s]
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to mnist\MNIST\raw\train-images-idx3-ubyte.gz
100%|████████████████████████████▉| 9895936/9912422 [02:10<00:00, 64784.97it/s]
Extracting mnist\MNIST\raw\train-images-idx3-ubyte.gz
0it [00:00, ?it/s][A
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to mnist\MNIST\raw\train-labels-idx1-ubyte.gz
0%| | 0/28881 [00:00<?, ?it/s][A
57%|██████████████████▋ | 16384/28881 [00:00<00:00, 54251.65it/s][A
32768it [00:01, 26629.83it/s] [A
0it [00:00, ?it/s][A
Extracting mnist\MNIST\raw\train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to mnist\MNIST\raw\t10k-images-idx3-ubyte.gz
0%| | 0/1648877 [00:00<?, ?it/s][A
1%|▎ | 16384/1648877 [00:00<00:32, 49498.48it/s][A
1%|▍ | 24576/1648877 [00:01<00:45, 35733.91it/s][A
2%|▊ | 40960/1648877 [00:01<00:46, 34744.99it/s][A
3%|█ | 57344/1648877 [00:02<00:41, 38561.02it/s][A
4%|█▏ | 65536/1648877 [00:02<00:45, 34578.56it/s][A
5%|█▌ | 81920/1648877 [00:02<00:40, 39063.12it/s][A
6%|█▊ | 98304/1648877 [00:03<00:35, 43615.46it/s][A
6%|█▉ | 106496/1648877 [00:03<00:37, 41326.50it/s][A
7%|██▏ | 122880/1648877 [00:03<00:36, 41545.08it/s][A
8%|██▌ | 139264/1648877 [00:03<00:33, 45165.26it/s][A
9%|██▊ | 155648/1648877 [00:04<00:29, 51452.48it/s][A
10%|███▏ | 172032/1648877 [00:04<00:28, 51839.76it/s][A
11%|███▎ | 180224/1648877 [00:05<00:51, 28616.56it/s][A
13%|███▉ | 212992/1648877 [00:05<00:39, 36618.44it/s][A
14%|████▏ | 229376/1648877 [00:05<00:35, 40157.12it/s][A
15%|████▍ | 245760/1648877 [00:06<00:39, 35613.66it/s][A
17%|█████ | 278528/1648877 [00:06<00:30, 44932.76it/s][A
18%|█████▎ | 294912/1648877 [00:06<00:28, 46938.38it/s][A
19%|█████▋ | 311296/1648877 [00:07<00:25, 51543.53it/s][A
20%|█████▉ | 327680/1648877 [00:07<00:25, 52503.22it/s][A
21%|██████▎ | 344064/1648877 [00:07<00:24, 53274.37it/s][A
22%|██████▌ | 360448/1648877 [00:07<00:23, 55020.87it/s][A
9920512it [02:20, 64784.97it/s] [A
24%|███████▏ | 393216/1648877 [00:08<00:21, 58606.12it/s][A
25%|███████▍ | 409600/1648877 [00:08<00:20, 59764.46it/s][A
26%|███████▉ | 434176/1648877 [00:09<00:18, 65222.93it/s][A
27%|████████▏ | 450560/1648877 [00:09<00:18, 64889.69it/s][A
29%|████████▋ | 475136/1648877 [00:09<00:22, 53273.85it/s][A
30%|████████▉ | 491520/1648877 [00:10<00:19, 59130.92it/s][A
32%|█████████▌ | 524288/1648877 [00:10<00:16, 68694.28it/s][A
33%|█████████▊ | 540672/1648877 [00:10<00:16, 66236.98it/s][A
34%|██████████▎ | 565248/1648877 [00:11<00:16, 67079.37it/s][A
35%|██████████▌ | 581632/1648877 [00:11<00:15, 67892.23it/s][A
37%|███████████ | 606208/1648877 [00:11<00:14, 69800.39it/s][A
38%|███████████▍ | 630784/1648877 [00:11<00:13, 73699.36it/s][A
39%|███████████▊ | 647168/1648877 [00:12<00:13, 73730.07it/s][A
41%|████████████▏ | 671744/1648877 [00:12<00:12, 77337.30it/s][A
42%|████████████▋ | 696320/1648877 [00:12<00:12, 77872.27it/s][A
44%|█████████████ | 720896/1648877 [00:13<00:11, 79581.47it/s][A
44%|█████████████▎ | 729088/1648877 [00:13<00:19, 46623.08it/s][A
46%|█████████████▊ | 761856/1648877 [00:13<00:15, 57099.09it/s][A
47%|██████████████▏ | 778240/1648877 [00:13<00:15, 54858.75it/s][A
48%|██████████████▍ | 794624/1648877 [00:14<00:14, 57738.84it/s][A
50%|██████████████▉ | 819200/1648877 [00:14<00:12, 65422.86it/s][A
51%|███████████████▏ | 835584/1648877 [00:14<00:11, 70076.20it/s][A
51%|███████████████▎ | 843776/1648877 [00:14<00:11, 70148.46it/s][A
52%|███████████████▋ | 860160/1648877 [00:14<00:10, 74306.13it/s][A
53%|███████████████▊ | 868352/1648877 [00:15<00:23, 33454.11it/s][A
55%|████████████████▌ | 909312/1648877 [00:15<00:16, 43678.81it/s][A
56%|████████████████▊ | 925696/1648877 [00:15<00:13, 53899.85it/s][A
57%|█████████████████▏ | 942080/1648877 [00:16<00:13, 54085.11it/s][A
58%|█████████████████▍ | 958464/1648877 [00:16<00:12, 54841.68it/s][A
59%|█████████████████▌ | 966656/1648877 [00:16<00:12, 54827.97it/s][A
59%|█████████████████▋ | 974848/1648877 [00:16<00:11, 57654.03it/s][A
60%|██████████████████ | 991232/1648877 [00:16<00:09, 66594.96it/s][A
61%|██████████████████▏ | 999424/1648877 [00:17<00:09, 66033.36it/s][A
62%|█████████████████▊ | 1015808/1648877 [00:17<00:08, 73957.73it/s][A
63%|██████████████████▏ | 1032192/1648877 [00:17<00:08, 68617.65it/s][A
64%|██████████████████▍ | 1048576/1648877 [00:17<00:07, 80297.70it/s][A
65%|██████████████████▋ | 1064960/1648877 [00:17<00:08, 69297.90it/s][A
66%|███████████████████ | 1081344/1648877 [00:18<00:07, 78336.17it/s][A
67%|███████████████████▎ | 1097728/1648877 [00:18<00:06, 86548.19it/s][A
68%|███████████████████▌ | 1114112/1648877 [00:18<00:07, 75619.59it/s][A
69%|███████████████████▉ | 1130496/1648877 [00:18<00:06, 78972.60it/s][A
70%|████████████████████▏ | 1146880/1648877 [00:18<00:06, 75580.64it/s][A
70%|████████████████████▎ | 1155072/1648877 [00:19<00:07, 68972.88it/s][A
71%|████████████████████▌ | 1171456/1648877 [00:19<00:06, 77656.71it/s][A
72%|████████████████████▉ | 1187840/1648877 [00:19<00:07, 59929.93it/s][A
74%|█████████████████████▎ | 1212416/1648877 [00:19<00:05, 74145.76it/s][A
75%|█████████████████████▌ | 1228800/1648877 [00:20<00:06, 65476.01it/s][A
76%|██████████████████████ | 1253376/1648877 [00:20<00:06, 64641.28it/s][A
77%|██████████████████████▎ | 1269760/1648877 [00:21<00:09, 40759.04it/s][A
79%|███████████████████████ | 1310720/1648877 [00:21<00:06, 51690.97it/s][A
80%|███████████████████████▎ | 1327104/1648877 [00:21<00:06, 53121.95it/s][A
81%|███████████████████████▋ | 1343488/1648877 [00:22<00:05, 55690.83it/s][A
82%|███████████████████████▉ | 1359872/1648877 [00:22<00:05, 56479.62it/s][A
83%|████████████████████████ | 1368064/1648877 [00:22<00:04, 61649.40it/s][A
83%|████████████████████████▏ | 1376256/1648877 [00:22<00:05, 54174.05it/s][A
84%|████████████████████████▎ | 1384448/1648877 [00:22<00:04, 59642.63it/s][A
84%|████████████████████████▍ | 1392640/1648877 [00:22<00:04, 54020.55it/s][A
85%|████████████████████████▊ | 1409024/1648877 [00:23<00:04, 55015.99it/s][A
86%|████████████████████████▉ | 1417216/1648877 [00:23<00:03, 60960.72it/s][A
87%|█████████████████████████▏ | 1433600/1648877 [00:23<00:04, 44963.53it/s][A
89%|█████████████████████████▊ | 1466368/1648877 [00:24<00:03, 55544.83it/s][A
89%|█████████████████████████▉ | 1474560/1648877 [00:24<00:03, 49591.63it/s][A
90%|██████████████████████████ | 1482752/1648877 [00:25<00:05, 28730.51it/s][A
91%|██████████████████████████▌ | 1507328/1648877 [00:25<00:03, 36281.07it/s][A
92%|██████████████████████████▊ | 1523712/1648877 [00:25<00:03, 40628.90it/s][A
93%|██████████████████████████▉ | 1531904/1648877 [00:25<00:02, 47066.75it/s][A
93%|███████████████████████████ | 1540096/1648877 [00:25<00:02, 39539.44it/s][A
94%|███████████████████████████▏ | 1548288/1648877 [00:26<00:02, 41905.03it/s][A
95%|███████████████████████████▌ | 1564672/1648877 [00:26<00:01, 45817.17it/s][A
95%|███████████████████████████▋ | 1572864/1648877 [00:26<00:01, 38341.60it/s][A
96%|███████████████████████████▊ | 1581056/1648877 [00:27<00:02, 23428.42it/s][A
97%|████████████████████████████▏| 1605632/1648877 [00:27<00:01, 31206.12it/s][A
98%|████████████████████████████▍| 1613824/1648877 [00:27<00:00, 37767.03it/s][A
98%|████████████████████████████▌| 1622016/1648877 [00:28<00:01, 22216.43it/s][A
100%|████████████████████████████▉| 1646592/1648877 [00:28<00:00, 27543.98it/s][A
0it [00:00, ?it/s][A[A
Extracting mnist\MNIST\raw\t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to mnist\MNIST\raw\t10k-labels-idx1-ubyte.gz
8192it [00:00, 14346.76it/s] [A[A
Extracting mnist\MNIST\raw\t10k-labels-idx1-ubyte.gz
Processing...
Done!
1654784it [00:48, 27543.98it/s] [A下载的数据自动做好标准化。
trainset 是数据集的变量名称。
torch.utils.data.dataloader.DataLoader# Compute the shape of the training set and testing set
trainset_shape = trainloader.dataset.train_data.shape
testset_shape = testloader.dataset.test_data.shape
# Print the computed shapes
print(trainset_shape, testset_shape)
# Compute the size of the minibatch for training set and testing set
trainset_batchsize = trainloader.batch_size
testset_batchsize = testloader.batch_size
# Print sizes of the minibatch
print(trainset_batchsize, testset_batchsize)torch.Size([60000, 28, 28]) torch.Size([10000, 28, 28])
32 32
D:\install\miniconda\lib\site-packages\torchvision\datasets\mnist.py:53: UserWarning: train_data has been renamed data
warnings.warn("train_data has been renamed data")
D:\install\miniconda\lib\site-packages\torchvision\datasets\mnist.py:58: UserWarning: test_data has been renamed data
warnings.warn("test_data has been renamed data")28x28 这是典型的图片数据。
这种分批导入的思想,需要打磨。
Define the class called Net which inherits from nn.Module
PyTorch 的使用中,定义类是常见的做法。
# Define the class Net
class Net(nn.Module):
# nn.Module
def __init__(self):
# Define all the parameters of the net
super(Net, self).__init__()
self.fc1 = nn.Linear(28 * 28 * 1, 200)
self.fc2 = nn.Linear(200, 10)
def forward(self, x):
# Do the forward pass
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x# Instantiate the Adam optimizer and Cross-Entropy loss function
optimizer = optim.Adam(model.parameters(), lr=3e-4)
criterion = nn.CrossEntropyLoss()
for batch_idx, data_target in enumerate(trainloader):
data = data_target[0]
target = data_target[1]
data = data.view(-1, 28 * 28)
optimizer.zero_grad()
# Complete a forward pass
output = model(data)
# Compute the loss, gradients and change the weights
loss = criterion(output, target)
loss.backward()
optimizer.step()---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-65-ee644993ab91> in <module>
3 criterion = nn.CrossEntropyLoss()
4
----> 5 for batch_idx, data_target in enumerate(trainloader):
6 data = data_target[0]
7 target = data_target[1]
D:\install\miniconda\lib\site-packages\torch\utils\data\dataloader.py in __next__(self)
558 if self.num_workers == 0: # same-process loading
559 indices = next(self.sample_iter) # may raise StopIteration
--> 560 batch = self.collate_fn([self.dataset[i] for i in indices])
561 if self.pin_memory:
562 batch = _utils.pin_memory.pin_memory_batch(batch)
D:\install\miniconda\lib\site-packages\torch\utils\data\dataloader.py in <listcomp>(.0)
558 if self.num_workers == 0: # same-process loading
559 indices = next(self.sample_iter) # may raise StopIteration
--> 560 batch = self.collate_fn([self.dataset[i] for i in indices])
561 if self.pin_memory:
562 batch = _utils.pin_memory.pin_memory_batch(batch)
D:\install\miniconda\lib\site-packages\torchvision\datasets\mnist.py in __getitem__(self, index)
93
94 if self.transform is not None:
---> 95 img = self.transform(img)
96
97 if self.target_transform is not None:
D:\install\miniconda\lib\site-packages\torchvision\transforms\transforms.py in __call__(self, img)
59 def __call__(self, img):
60 for t in self.transforms:
---> 61 img = t(img)
62 return img
63
D:\install\miniconda\lib\site-packages\torchvision\transforms\transforms.py in __call__(self, tensor)
162 Tensor: Normalized Tensor image.
163 """
--> 164 return F.normalize(tensor, self.mean, self.std, self.inplace)
165
166 def __repr__(self):
D:\install\miniconda\lib\site-packages\torchvision\transforms\functional.py in normalize(tensor, mean, std, inplace)
206 mean = torch.as_tensor(mean, dtype=torch.float32, device=tensor.device)
207 std = torch.as_tensor(std, dtype=torch.float32, device=tensor.device)
--> 208 tensor.sub_(mean[:, None, None]).div_(std[:, None, None])
209 return tensor
210
IndexError: too many indices for tensor of dimension 0# Set the model in eval mode
model.eval()
for i, data in enumerate(testloader, 0):
inputs, labels = data
# Put each image into a vector
inputs = inputs.view(-1, 28 * 28)
# Do the forward pass and get the predictions
outputs = model(inputs)
_, outputs = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (outputs == labels).sum().item()
print('The testing set accuracy of the network is: %d %%' % (100 * correct / total))---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-68-4abe7f84ec52> in <module>
2 model.eval()
3
----> 4 for i, data in enumerate(testloader, 0):
5 inputs, labels = data
6
D:\install\miniconda\lib\site-packages\torch\utils\data\dataloader.py in __next__(self)
558 if self.num_workers == 0: # same-process loading
559 indices = next(self.sample_iter) # may raise StopIteration
--> 560 batch = self.collate_fn([self.dataset[i] for i in indices])
561 if self.pin_memory:
562 batch = _utils.pin_memory.pin_memory_batch(batch)
D:\install\miniconda\lib\site-packages\torch\utils\data\dataloader.py in <listcomp>(.0)
558 if self.num_workers == 0: # same-process loading
559 indices = next(self.sample_iter) # may raise StopIteration
--> 560 batch = self.collate_fn([self.dataset[i] for i in indices])
561 if self.pin_memory:
562 batch = _utils.pin_memory.pin_memory_batch(batch)
D:\install\miniconda\lib\site-packages\torchvision\datasets\mnist.py in __getitem__(self, index)
93
94 if self.transform is not None:
---> 95 img = self.transform(img)
96
97 if self.target_transform is not None:
D:\install\miniconda\lib\site-packages\torchvision\transforms\transforms.py in __call__(self, img)
59 def __call__(self, img):
60 for t in self.transforms:
---> 61 img = t(img)
62 return img
63
D:\install\miniconda\lib\site-packages\torchvision\transforms\transforms.py in __call__(self, tensor)
162 Tensor: Normalized Tensor image.
163 """
--> 164 return F.normalize(tensor, self.mean, self.std, self.inplace)
165
166 def __repr__(self):
D:\install\miniconda\lib\site-packages\torchvision\transforms\functional.py in normalize(tensor, mean, std, inplace)
206 mean = torch.as_tensor(mean, dtype=torch.float32, device=tensor.device)
207 std = torch.as_tensor(std, dtype=torch.float32, device=tensor.device)
--> 208 tensor.sub_(mean[:, None, None]).div_(std[:, None, None])
209 return tensor
210
IndexError: too many indices for tensor of dimension 03 CNN

Convolution 的必要性
- 变量之间不是独立的
- 参数太多太难训练,需要降维
- 参数多容易过拟合
3.1 Convolution operator
Convolution operator Elezi (2019) 算是解释得比较清楚的了,好好学习。 有两种编程方式
- OOP
- Functional
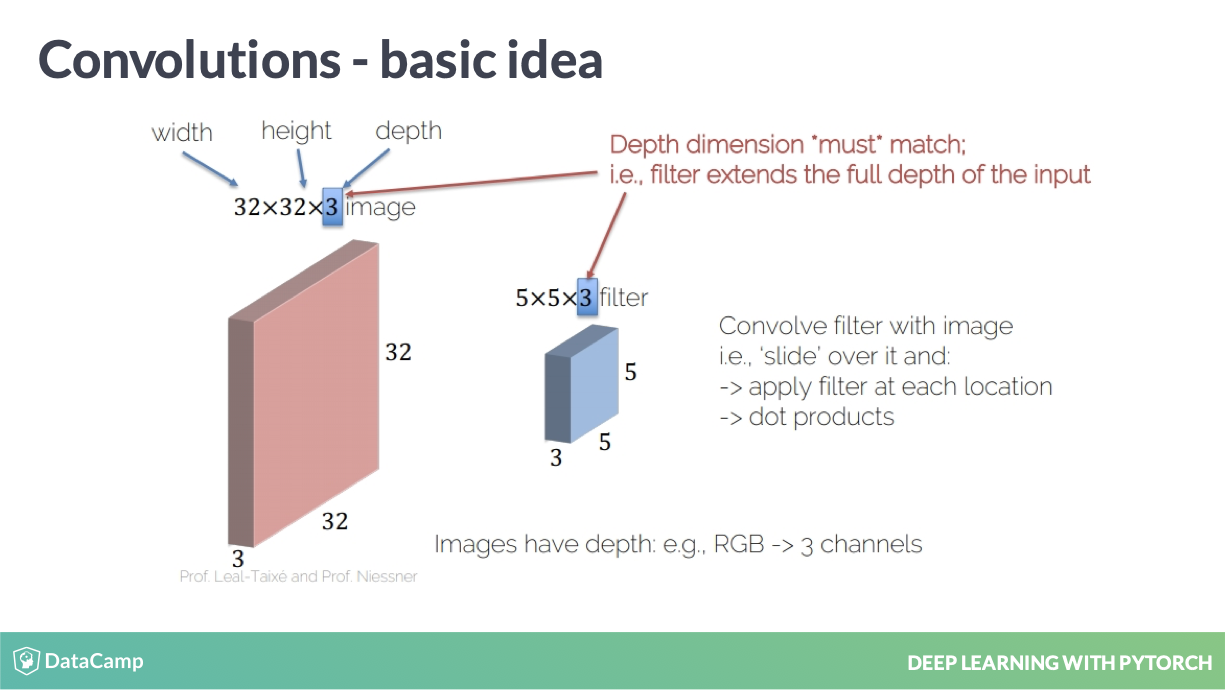
filter 的定义
这里解释了 filter 是如何运行的,并且 channels 是如何定义的。
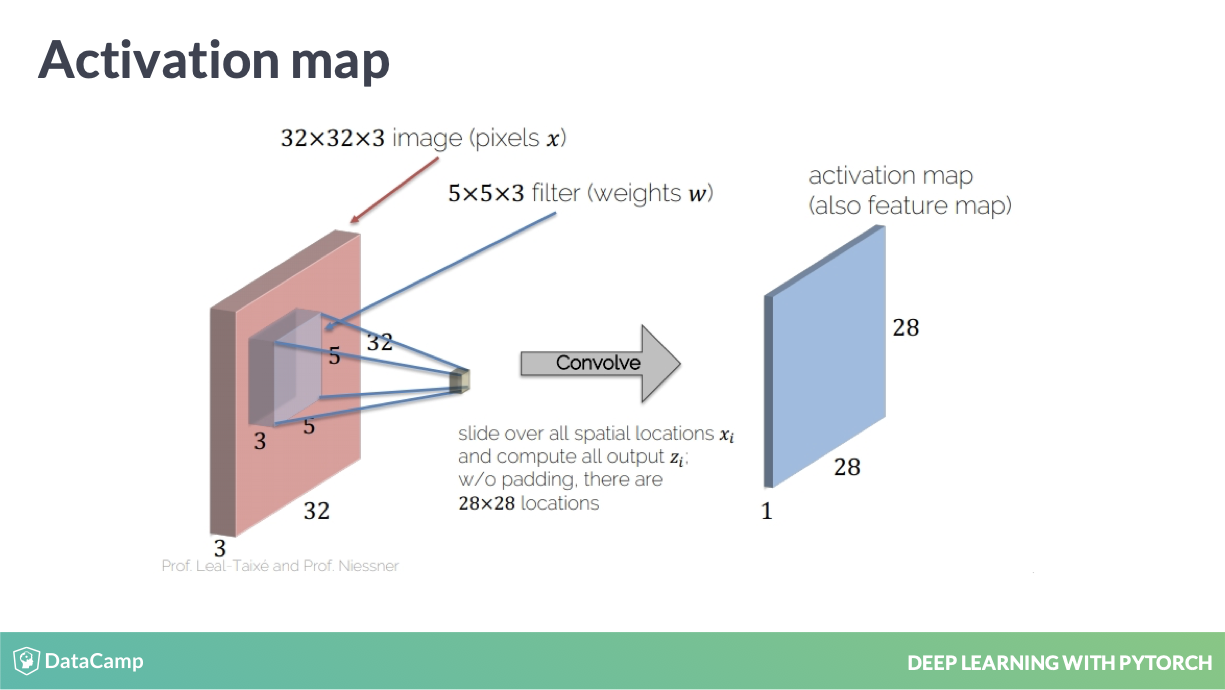
filter 中的 weight 实现
filter 其实就是一个 weight 矩阵,实现了一个降低维度的手段。
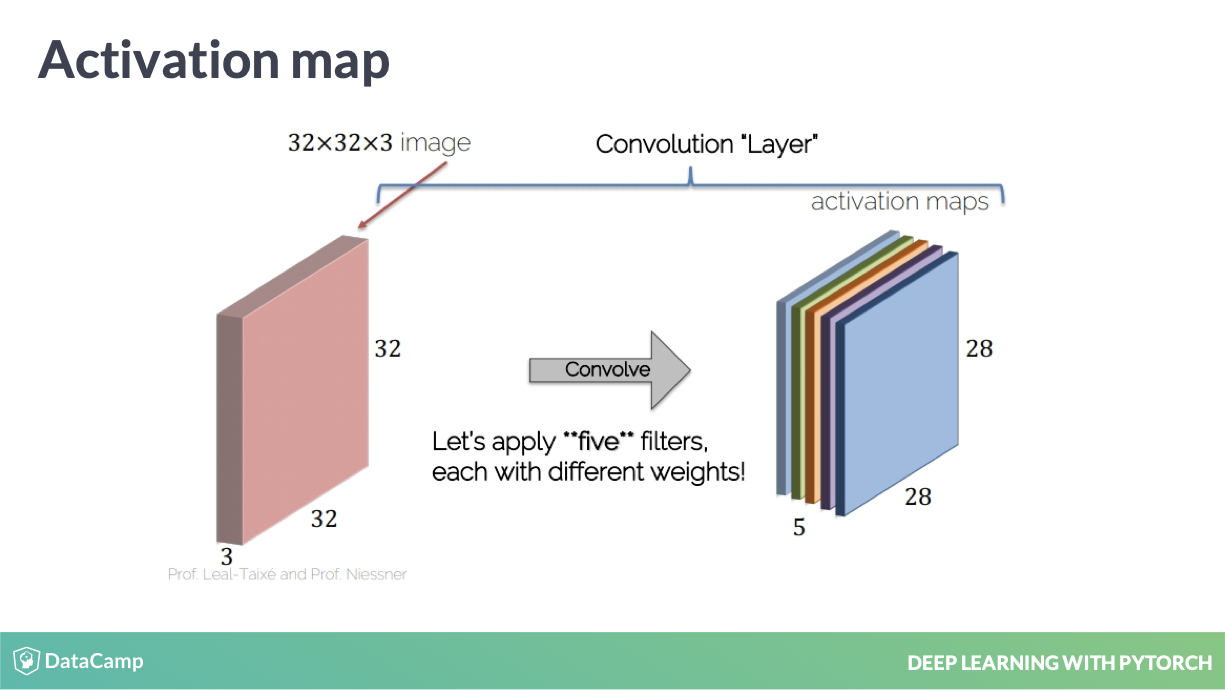
多个 filters
当然这个 filter 是可以多个的,也就是 out_channels 的定义。
# Create 10 random images of shape (1, 28, 28)
images = torch.rand(10, 1, 28, 28)
# Build 6 conv. filters
conv_filters = torch.nn.Conv2d(in_channels=1, out_channels=6, kernel_size=3, stride=1, padding=1)
# Convolve the image with the filters
output_feature = conv_filters(images)
print(output_feature.shape)torch.rand(10, 1, 28, 28) 建立十个图片,单色,因此 in_channels=1
filter 大小为 (3, 3),因此 kernel_size=3
建立6个 filter,因此 out_channels=6
这是函数化编程的方式
# Create 10 random images
image = torch.rand(10, 1, 28, 28)
# Create 6 filters
filters = torch.rand(6, 1, 3, 3)
# Convolve the image with the filters
output_feature = F.conv2d(image, filters, stride=1, padding=1)
print(output_feature.shape)定义好 filters 进行训练。
3.2 Pooling operators
Pooling operators 是另外一种降维手段。
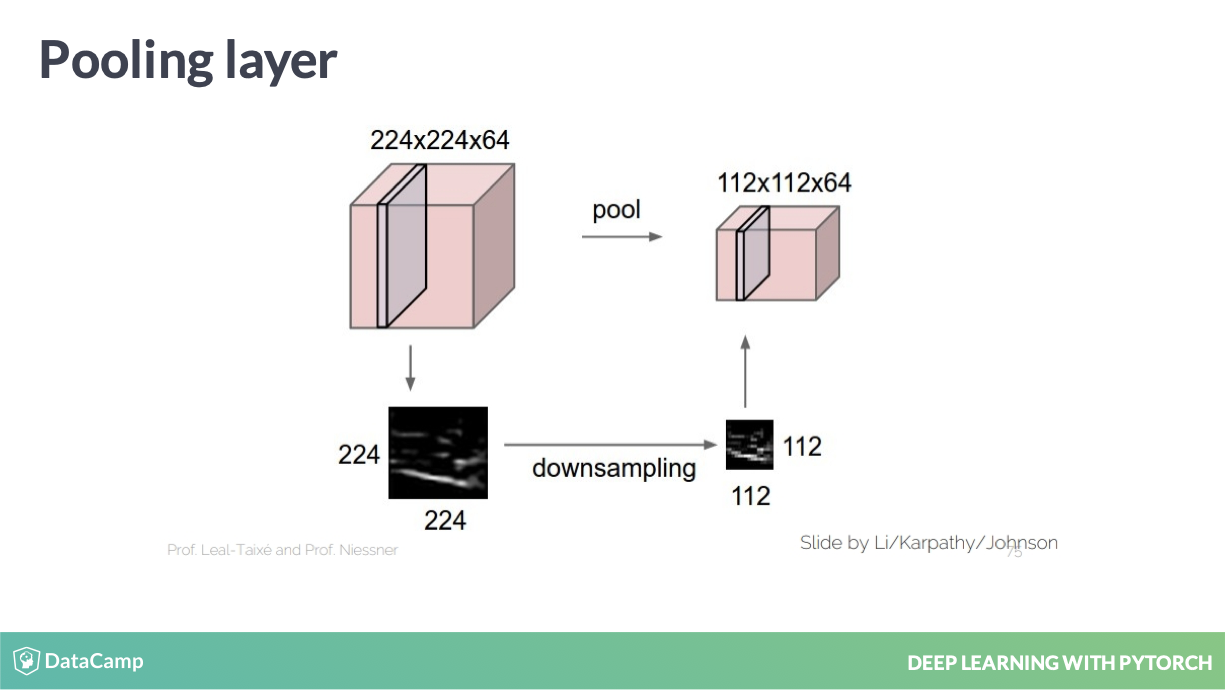
Pooling operators
这是实现的直观表现,其实就是暴力地缩小图片。
Max-Pooling
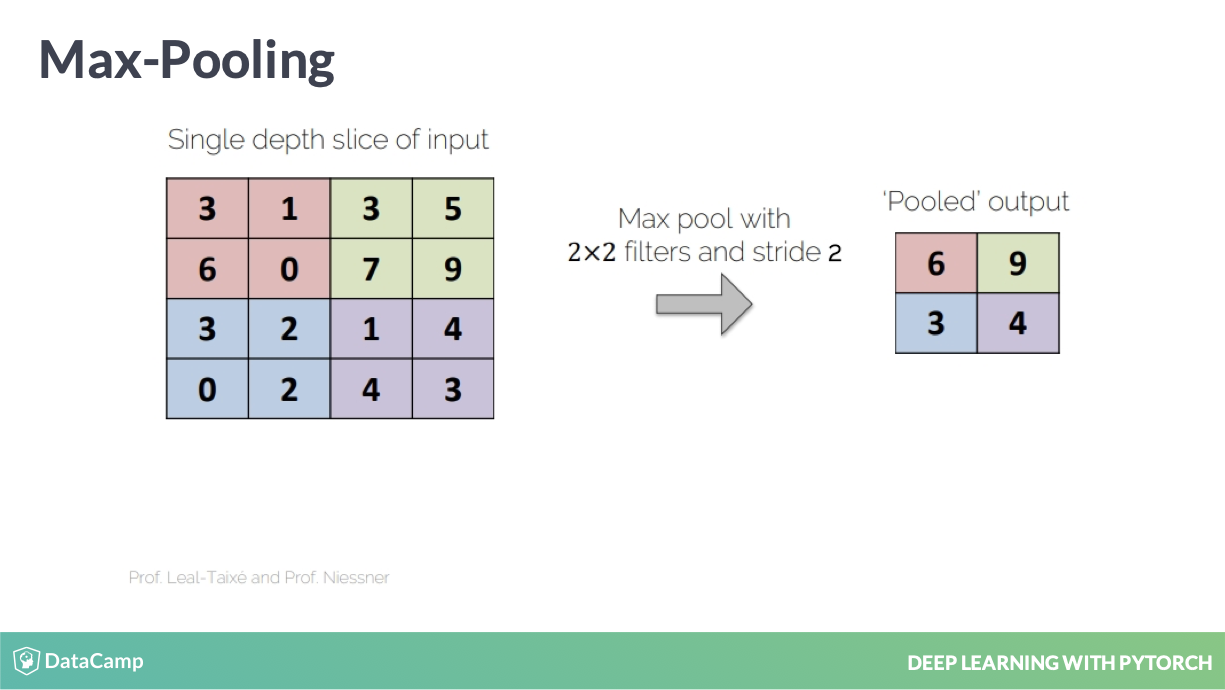
image
Max-Pooling
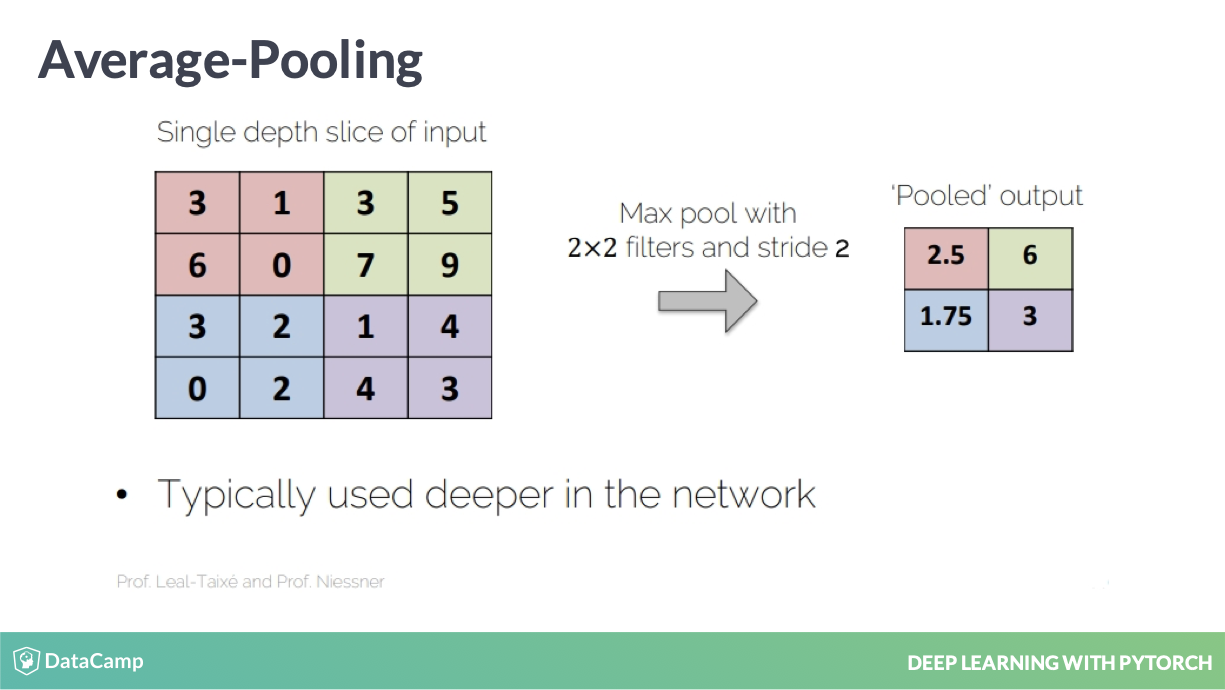
Average-Pooling
import torch
import torch.nn.functional as F
im = torch.tensor([[[[ 8., 1., 2., 5., 3., 1.],
[ 6., 0., 0., -5., 7., 9.],
[ 1., 9., -1., -2., 2., 6.],
[ 0., 4., 2., -3., 4., 3.],
[ 2., -1., 4., -1., -2., 3.],
[ 2., -4., 5., 9., -7., 8.]]]])
im.shape # 1 img, 1 channel, 6x6 size
# Build a pooling operator with size `2`.
max_pooling = torch.nn.MaxPool2d(2)
# Apply the pooling operator
output_feature = max_pooling(im)
# Use pooling operator in the image
output_feature_F = F.max_pool2d(im, 2)
# 更加理解函数化编程了,每个都尽量以参数形式进行编程,而非 OOP 都是一个个函数套用。
# print the results of both cases
print(output_feature)
print(output_feature_F)3.3 AlexNet
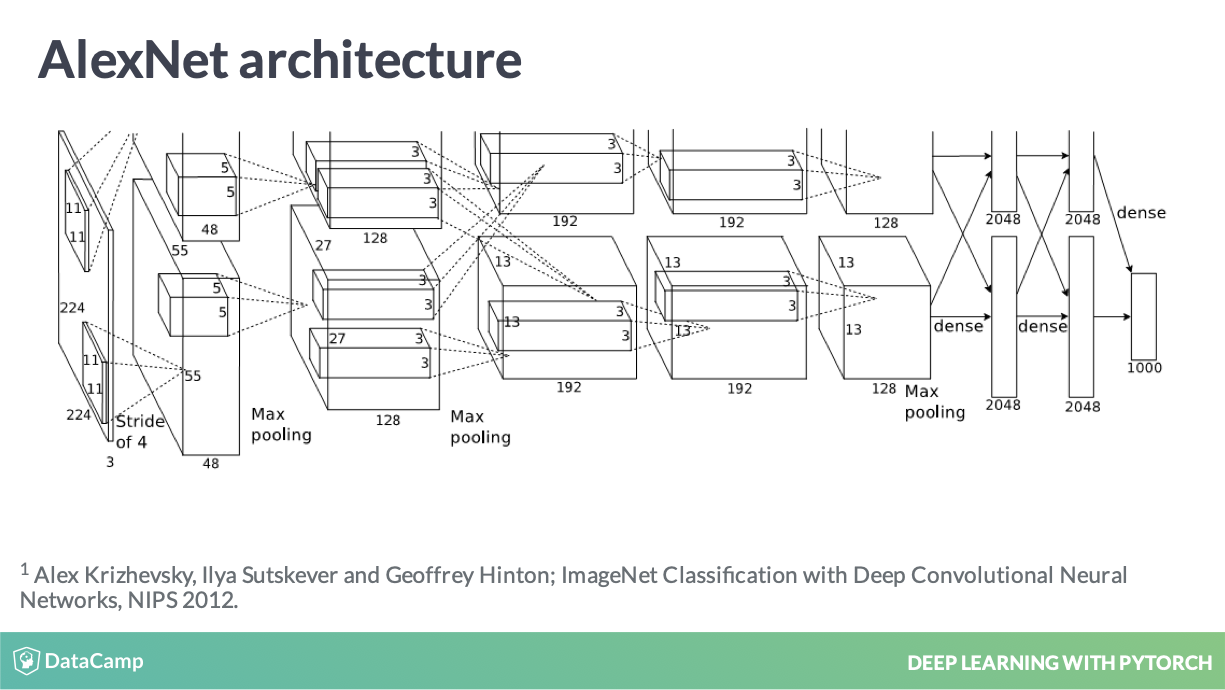
AlexNet 是以 pooling operators 实现的
AlexNet, CNN 好复杂,用了好多降维的手段。
class Net(nn.Module):
def __init__(self, num_classes):
super(Net, self).__init__()
# Instantiate the ReLU nonlinearity
self.relu = nn.ReLU()
# Instantiate two convolutional layers
self.conv1 = nn.Conv2d(in_channels=1, out_channels=5, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(in_channels=5, out_channels=10, kernel_size=3, padding=1)
# Instantiate a max pooling layer
self.pool = nn.MaxPool2d(2, 2)
# Instantiate a fully connected layer
self.fc = nn.Linear(7 * 7 * 10, 10)
def forward(self, x):
# Apply conv followd by relu, then in next line pool
x = self.relu(self.conv1(x))
x = self.pool(x)
# Apply conv followd by relu, then in next line pool
x = self.relu(self.conv2(x))
x = self.pool(x)
# Prepare the image for the fully connected layer
x = x.view(-1, 7 * 7 * 10)
# (height * width * num_channels)
# Apply the fully connected layer and return the result
return self.fc(x)感觉后面慢慢复杂起来了。
更加完备的一个网络
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2) self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2)
self.conv2 = nn.Conv2d(64, 192, kernel_size=5, padding=2) self.conv3 = nn.Conv2d(192, 384, kernel_size=3, padding=1) self.conv4 = nn.Conv2d(384, 256, kernel_size=3, padding=1) self.conv5 = nn.Conv2d(256, 256, kernel_size=3, padding=1) self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.fc1 = nn.Linear(256 * 6 * 6, 4096)
self.fc2 = nn.Linear(4096, 4096)
self.fc3 = nn.Linear(4096, num_classes)
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.maxpool(x)
x = self.relu(self.conv2(x))
x = self.maxpool(x)
x = self.relu(self.conv3(x))
x = self.relu(self.conv4(x))
x = self.relu(self.conv5(x))
x = self.maxpool(x)
x = self.avgpool(x)
x = x.view(x.size(0), 256 * 6 * 6) x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
return self.fc3(x)
net = AlexNet()这部分是 slides 上的代码,我觉得更加具备参考价值。
import torch
import torchvision
import torchvision.transforms as transforms import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optimtransform = transforms.Compose( [transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)class Net(nn.Module):
def __init__(self, num_classes=10):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, padding=1) self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1) self.conv3 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1) self.pool = nn.MaxPool2d(2, 2)
self.fc = nn.Linear(128 * 4 * 4, num_classes)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = self.pool(F.relu(self.conv3(x))) x = x.view(-1, 128 * 4 * 4)
return self.fc(x)Training a CNN
for epoch in range(10):
for i, data in enumerate(trainloader, 0):
# Get the inputs
inputs, labels = data
# Zero the parameter gradients
optimizer.zero_grad()
# Forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels) loss.backward()
optimizer.step()correct, total = 0, 0
predictions = []
net.eval()
for i, data in enumerate(testloader, 0):
inputs, labels = data
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1) predictions.append(outputs)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('The testing set accuracy of the network is: %d %%' % ( 100 * correct / total))4 训练模块
4.1 The sequential module
The sequential module 类似于 keras,但是还是要在 init 里面定义完。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# Declare all the layers for feature extraction
self.features = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=5, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=5, out_channels=10, kernel_size=3, padding=1),
nn.MaxPool2d(2, 2), nn.ReLU(inplace=True),
nn.Conv2d(in_channels=10, out_channels=20, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=20, out_channels=40, kernel_size=3, padding=1),
nn.MaxPool2d(2, 2), nn.ReLU(inplace=True))
# Declare all the layers for classification
self.classifier = nn.Sequential(nn.Linear(7 * 7 * 40, 1024), nn.ReLU(inplace=True),
nn.Linear(1024, 2048), nn.ReLU(inplace=True),
nn.Linear(2048, 10))nn.Sequential 写得非常好。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# Declare all the layers for feature extraction
self.features = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=5, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=5, out_channels=10, kernel_size=3, padding=1),
nn.MaxPool2d(2, 2), nn.ReLU(inplace=True),
nn.Conv2d(in_channels=10, out_channels=20, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=20, out_channels=40, kernel_size=3, padding=1),
nn.MaxPool2d(2, 2), nn.ReLU(inplace=True))
# Declare all the layers for classification
self.classifier = nn.Sequential(nn.Linear(7 * 7 * 40, 1024), nn.ReLU(inplace=True),
nn.Linear(1024, 2048), nn.ReLU(inplace=True),
nn.Linear(2048, 10))
def forward():
# Apply the feature extractor in the input
x = self.features(x)
# Squeeze the three spatial dimensions in one
x = x.view(-1, 7 * 7 * 10)
# Classify the images
x = self.classifier(x)
return x4.2 Regularization techniques
overfitting
- Training set: train the model
- Validation set: select the model
- Testing set: test the model
这个分类方式很好。
L2-regularization
\[C=-\frac{1}{n} \sum_{x j}\left[y_{j} \ln a_{j}^{L}+\left(1-y_{j}\right) \ln \left(1-a_{j}^{L}\right)\right]+\frac{\lambda}{2 n} \sum_{w} w^{2}\]
Dropout
参考 Srivastava et al. (2014)
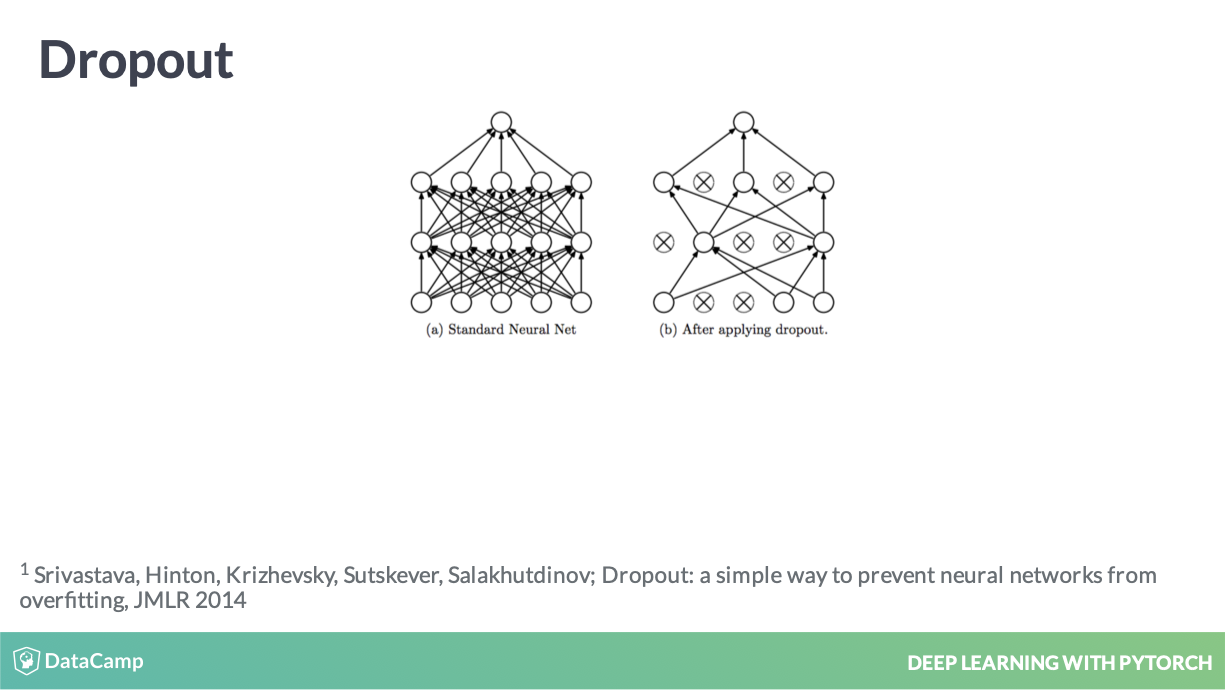
Dropout 实现过程
class Net(nn.Module):
def __init__(self):
# Define all the parameters of the net
self.classifier = nn.Sequential(
nn.Linear(28*28, 200),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(200, 500),
nn.ReLU(inplace=True),
nn.Linear(500, 10))Batch-normalization
参考 Ioffe and Szegedy (2015)

BN 实现的伪代码
4.3 Transfer learning
迁移学习,我目前就是觉得太多了,那么多层需要定义,电脑也跑不动啊 !
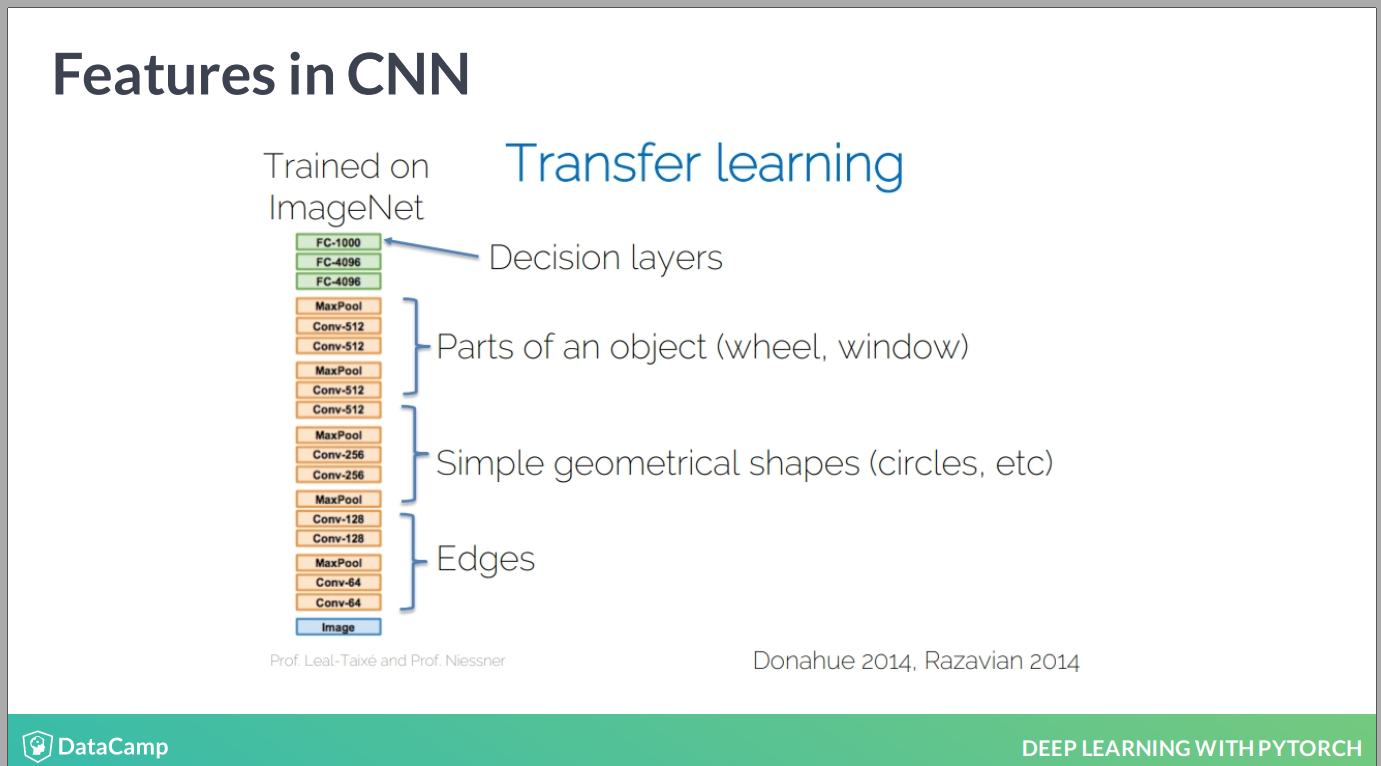
理想化的神经网络结构
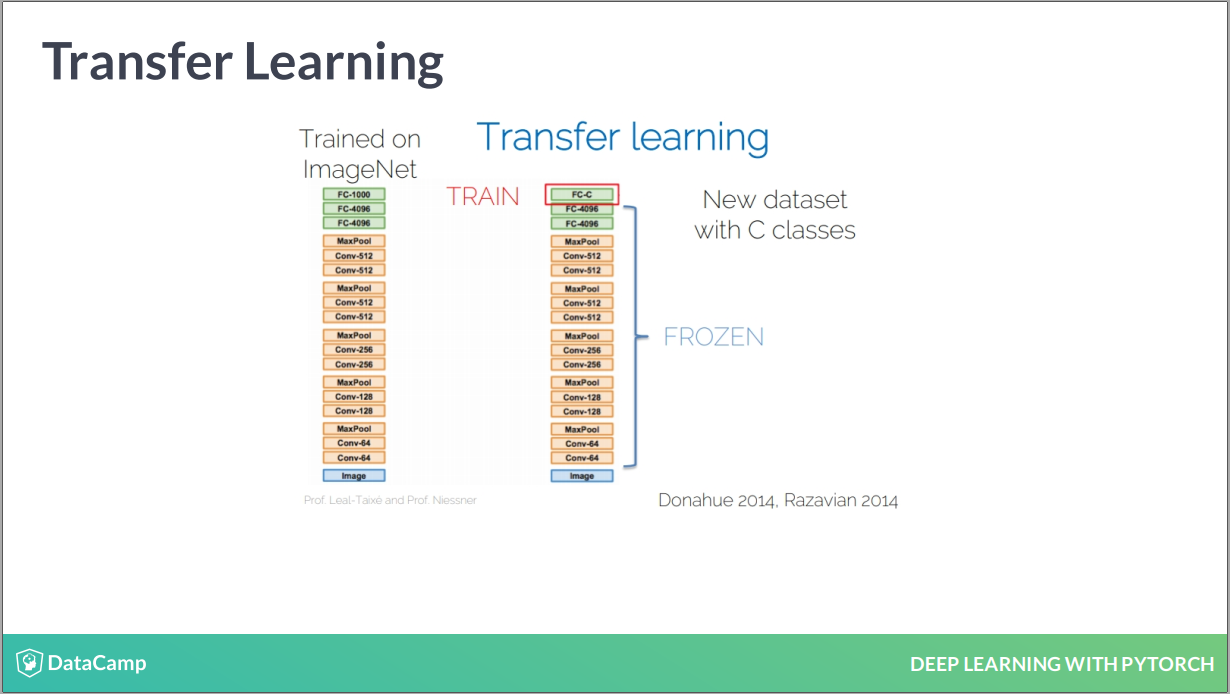
引入新的小数据,使用大数据训练的模型
不是去 training by scratch,而是用一个小数据去再训练这个模型,因为数据小,所以训练很快。

实现的 PyTorch 代码
只需要修改 out_channels 和 input 结构就好。
作者的一个建议是好的,就是当不熟悉 CNN 时,可以找一个训练好的,然后迁移学习。
you’ll create a new model using this training set, but the accuracy will be poor. Next, you’ll perform the same training, but you’ll start with the parameters from your digit classifying model. Even though digits and letters are two different classification problems, you’ll see that using information from your previous model will dramatically improve this one.
一个是字母,一个是数字,相当于模型从 pre-trained 模型开始梯度下降。
# Create a new model
model = Net()
# Change the number of out channels
model.fc = nn.Linear(7 * 7 * 512, 26)
# Train and evaluate the model
model.train()
train_net(model, optimizer, criterion)
print("Accuracy of the net is: " + str(model.eval()))# Create a new model
model = Net()
# Load the parameters from the old model
model.load_state_dict(torch.load('my_net.pth'))
# Change the number of out channels
model.fc = nn.Linear(7 * 7 * 512, 26)
# Train and evaluate the model
model.train()
train_net(model, optimizer, criterion)
print("Accuracy of the net is: " + str(model.eval()))果然 pre-train 模型是精细化处理的,所以效果更好,准确率更高。
Excellent! By incorporating information from the previously trained model, we are able to get a good model for handwritten digits, even with a small training set!
怎么理解呢?因为神经网络需要大量的数据进行训练,但是这里只是一个很小的数据集,因此再怎么训练,模型也不会好,因此需要一个用之前信息预训练好的模型,这相当于是利用之前的大量数据了,因此再用一个小数据集再训练模型时,效果会很好。
You already finetuned a net you had pretrained. In practice though, it is very common to finetune CNNs that someone else (typically the library’s developers) have pretrained in ImageNet. Big networks still take a lot of time to be trained on large datasets, and maybe you cannot afford to train a large network on a dataset of 1.2 million images on your laptop.
这个例子举例很好。
Instead, you can simply download the network and finetune it on your dataset. That’s what you will do right now. You are going to assume that you have a personal dataset, containing the images from all your last 7 holidays. You want to build a neural network that can classify each image depending on the holiday it comes from. However, since the dataset is so small, you need to use the finetuning technique.
这是作者的一个假设。
附录
4.4 完成证书
参考文献
Elezi, Ismail. 2019. “Deep Learning with Pytorch.” DataCamp. 2019. https://www.datacamp.com/courses/deep-learning-with-pytorch.
Ioffe, Sergey, and Christian Szegedy. 2015. “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift.”
Srivastava, Nitish, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. “Dropout: A Simple Way to Prevent Neural Networks from Overfitting.” Journal of Machine Learning Research 15 (1): 1929–58.