凤凰金融 (Phoenix Finance) 量化投资大赛 参赛笔记
2019-07-01
knitr::opts_chunk$set(warning = FALSE, message = FALSE, eval=F)
library(tidyverse)- 使用 RMarkdown 的
child参数,进行文档拼接。 - 这样拼接以后的笔记方便复习。
- 相关问题提交到 GitHub
1 前言
为了保持文档的简洁性,参数设置为eval=F,即本文代码只展示不发生。
1.1 文件注释(整合成表格)
1.2 新增内容
- 2.22 组合\(\beta\)逻辑 \(\frac{\alpha_{\mathrm{portfolio}}}{\beta_{\mathrm{portfolio}}}\)
- 2.4 是否有超过涨跌停板的价格
- 2.21 金工报告阅读
- 2.20 Y变量定义为半年的Sharpe Ratio
- 2.19 实验设计思路
1.3 比赛要求
比赛对异常值处理要求还是比较高的。
4月27日round2结束。
1.4 %>% 的debug思路
这里debug的思想,和python的pdb.set_trace()类似。
get_distinct_value_leq_10 <- function(x){
x %>%
filter(mpg >= 10) %>%
group_by(cyl) %>%
count()
}
get_distinct_value_leq_10(mtcars)%>%主要就是方便debug,如上面这个代码,是一个函数,这个函数应用到mtcars表格,将函数拆开,替换x为mtcars。
mtcarsmtcars %>%
filter(mpg >= 10)mtcars %>%
filter(mpg >= 10) %>%
group_by(cyl)mtcars %>%
filter(mpg >= 10) %>%
group_by(cyl) %>%
count()然后依次的跑,这样你就可以看到每一步有什么变化,从而来debug,比如出现了NA,出现了异常值,或者跟你对照的表格setequal。
2 数据处理
2.1 合并数据
2.1.1 round1和round2是否交集为0
round1和round2是否交集为0这个函数会很慢,不建议跑。
get_data_nest <- function(x){
file.path(getwd(),x) %>%
dir() %>%
as_tibble() %>%
mutate(rank = str_extract(value,"[:digit:]{1,4}"),
rank = as.integer(rank)) %>%
arrange(rank) %>%
mutate(path = file.path(getwd(),"data",x,value)) %>%
mutate(table = map(path,read_csv))
}
equal_or_not <- function(x,y){
all_data_round1 <- get_data_nest(x)
all_data_round2 <- get_data_nest(y)
all_data_round1_for_join <-
all_data_round1 %>%
select(value,table) %>%
rename(table_round1 = table)
all_data_round2_for_join <-
all_data_round2 %>%
select(value,table) %>%
rename(table_round2 = table)
all_data_round1_for_join %>%
left_join(all_data_round2_for_join, by = "value") %>%
mutate(equal_or_not = map2(table_round1,table_round2,~setequal(.x,.y)[[1]])) %>%
select(value,equal_or_not) %>%
unnest()
}equal_or_not("round1","round2")2.1.2 合并数据
all_data <- read_csv(file.path("data","round4_files","all_data.csv"))2.2 交易日历
full_data_w_vars <-
expand.grid(rank = unique(all_data$rank),
code = unique(all_data$code)) %>%
left_join(all_data,by = c("rank","code"))
full_data <-
full_data_w_vars %>%
select(1:3) 2.3 剔除收盘价数据缺失 top 10%
2.3.1 10%的名单
miss_perf <-
full_data %>%
group_by(code) %>%
summarise(n_miss = sum(is.na(close))) %>%
ungroup() %>%
write_csv(file.path("data","round4_files","n_miss_cumsum_num_xiaosong.csv"))
cutoff <-
miss_perf %>%
group_by(n_miss) %>%
count() %>%
ungroup() %>%
mutate(cumsum_miss = cumsum(n)/sum(n)) %>%
write_csv(file.path("data","round4_files","n_miss_cumsum_xiaosong.csv")) %>%
filter(cumsum_miss >= 0.9) %>%
.[1,1] %>%
pull()
mt_list <-
miss_perf %>%
filter(n_miss < cutoff) %>%
.$code这里只删除缺失最多前10%。
f_list <- names(full_data_w_vars) %>% str_subset("f\\d{1,2}|close")2.3.2 boxplot outlier detector
remove_outliers <- function(x, na.rm = TRUE, ...) {
qnt <- quantile(x, probs=c(.25, .75), na.rm = na.rm, ...)
H <- 1.5 * IQR(x, na.rm = na.rm)
y <- x
y[x < (qnt[1] - H)] <- NA
y[x > (qnt[2] + H)] <- NA
y
}stable_vars_list <-
full_data_w_vars %>%
group_by(code) %>%
summarise_at(f_list,sd, na.rm = TRUE) %>%
ungroup() %>%
gather(key,value,f_list) %>%
group_by(key) %>%
summarise(mean_sd = mean(value)) %>%
arrange(mean_sd) %>%
mutate(mean_sd = (round(mean_sd*1000))) %>%
filter(mean_sd < 100) %>%
.$keyf_list
stable_vars_list
unstable_vars_list <- setdiff(f_list,stable_vars_list)
unstable_vars_listfull_data_outlier2miss <-
full_data_w_vars %>%
# 异常值变成NA
ungroup() %>%
group_by(code) %>%
# Inf值直接作为NA
mutate_at(f_list,function(x){ifelse(is.infinite(x),NA,x)}) %>%
mutate_at(unstable_vars_list,remove_outliers)
full_data_outlier2miss %>%
group_by(code) %>%
summarise_all(funs(sum(is.na(.)))) %>%
write_csv(file.path("data","round4_files","all_miss_perf.csv"))full_data_ipt_miss <-
full_data_outlier2miss %>%
filter(code %in% mt_list) %>%
# 缺失值查看
# summarise_all(funs(sum(is.na(.))))
ungroup() %>%
group_by(code) %>%
tidyr::fill(f_list) %>% # 向下补
tidyr::fill(f_list, .direction = c("up")) %>% # 向上补
ungroup()all_miss_perf.csv:
异常值\(\to\)NA,NA的汇总情况。
下载地址:
https://raw.githubusercontent.com/JiaxiangBU/picbackup/master/all_miss_perf.csv
full_data_ipt_miss %>% anyNA()
full_data_ipt_miss %>%
ungroup() %>%
summarise_each(funs(sum(is.infinite(.)))) %>%
gather() %>%
summarise(sum(value))2.4 \(\surd\) 是否有超过涨跌停板的价格
这里存在股票split的情况,比如1:2的切分时, 后面的股价也全部都减半了,因此特别影响计算收益率。 这里的处理是使用日度收益率而非日度价格,将涨跌幅超过10%的做 top bottom 处理。 因为正常收益率不会因为后期 top bottom 处理而发生改变。
相当于假设 \[P_1 = 10, P_2 = 12, P_3 = 13.2\]
这里处理成
\[r_1 = \frac{P_2'-P_1}{P_1} = \frac{11 - 10}{10} = 10\%\] \[r_2 = \frac{P_3-P_2}{P_2} = \frac{13.1 - 12}{12} = 10\%\]
upper_lower_10pctg <- function(x){
x %>%
select(rank,code,close) %>%
group_by(code) %>%
# mutate(daily_return = log(close),
# daily_return = c(NA,diff(daily_return))) %>%
mutate(daily_return = close/lag(close)-1) %>%
ungroup() %>%
filter(!is.na(daily_return)) %>%
summarise(max = max(daily_return),
min = min(daily_return),
avg = mean(daily_return),
outlier = sum(abs(daily_return) > 0.1)/nrow(x)) %>%
mutate_all(.funs = percent)
}upper_lower_10pctg(full_data_ipt_miss)max: 所有股票日收益率最大值min: 所有股票日收益率最小值avg: 所有股票日收益率平均值outlier: 所有股票日收益率大于10%或者小于10%占总样本的比例
__超过涨跌停板的价格__的修正还有点复杂,因为我发现修改好,异常值率还增加了。 这个我想到的原因,但是还不好用语言表达,我明天反馈。 异常值率还是比较低的,因此你们可以照常用。
2.4.1 存在的bug问题
full_data_ipt_miss %>%
select(rank,code,close) %>%
filter(code == 'stock100000') %>%
head(100) %>%
# group_by(code) %>%
mutate(close = upper_lower_10(close)) %>%
# filter(close != close2) %>%
slice(80:82) %>%
mutate(r = close/lag(close)-1,
abs_r = abs(r),
abs_r_10 = abs_r * 10,
result = if_else(abs_r_10 > 1, 1, 0)) %>%
write_csv(file.path("data","round4_files","debug_file.csv"))
# upper_lower_10pctg()这是R的问题。
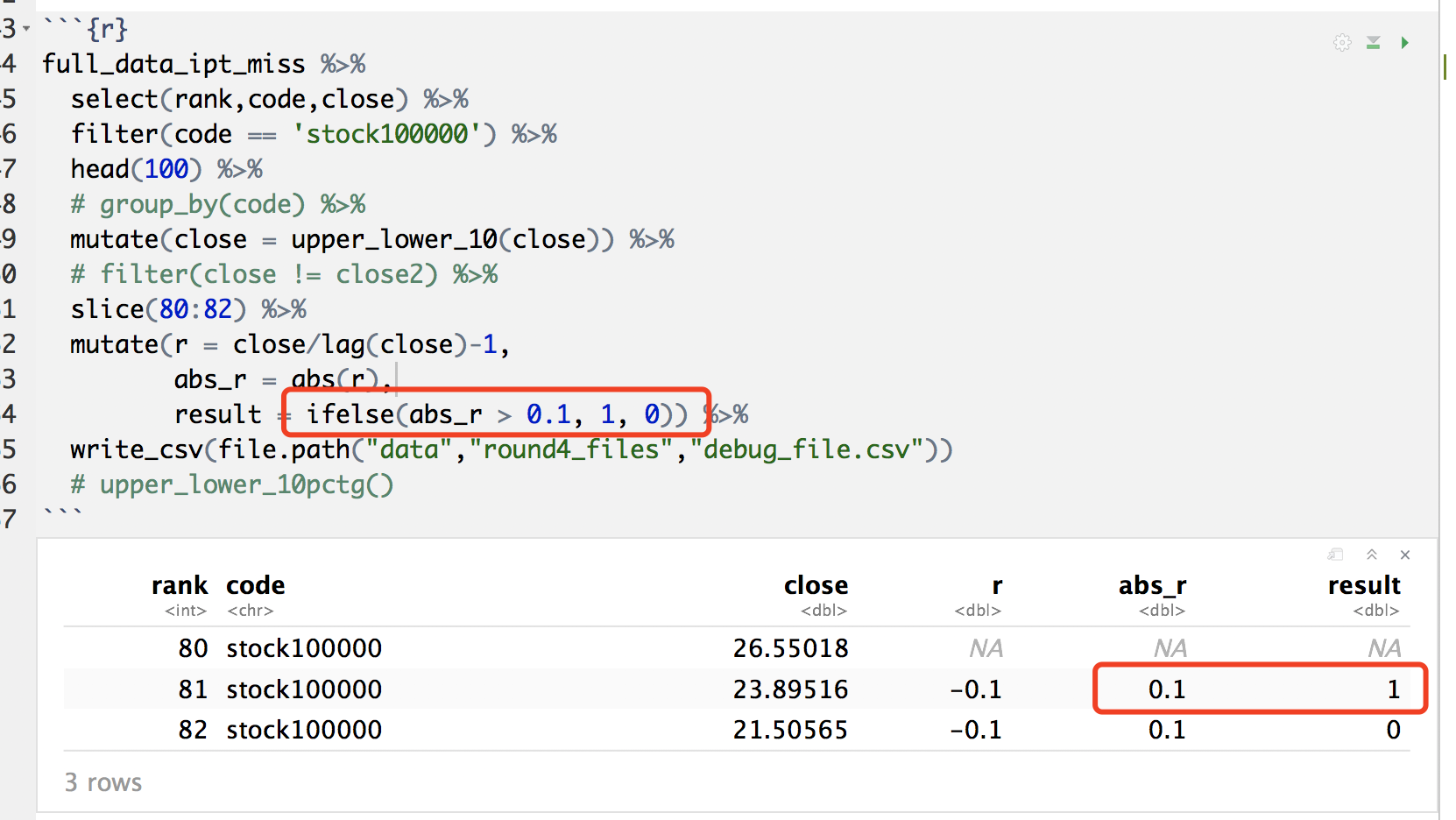
这个问题不解决,没办法操作。
options(digits = 4)
read_csv(file.path("data","round4_files","debug_file.csv")) %>%
mutate(
close = round(close, 2),
result2 = if_else(as.numeric(abs_r) > 0.1, 1, 0))options(digits = 20) 可以观测数据20位小数的状态,因此以上 debug 问题引刃而解。
filter(code == 'stock100000') %>%
rank
77 78 变成了一半。
这个时候要乘以。
2.4.2 处理步骤
full_data_ipt_miss_outlier <-
full_data_ipt_miss %>%
# head(1000) %>%
group_by(code) %>%
mutate(return = log(close) - lag(log(close)),
return = case_when(
is.na(return) ~ 0,
return > 0.1 ~ 0.1,
return < -0.1 ~ -0.1,
abs(return) <= 0.1 ~ return)
) %>%
# 检验函数
# ungroup() %>%
# na.omit() %>%
# summarise(max(return),min(return))
# 拿到首日价格
# mutate(first_price = first(close)) %>%
# select(first_price,close)
mutate(close = cumprod(1+return)*first(close)) %>%
select(-return)upper_lower_10pctg(full_data_ipt_miss_outlier)2.5 插入半年收益率
2.5.1 逻辑
\[\begin{alignat}{2} y_t &= F_t \cdot \beta + \mu_t \\ y_{t-135} &= F_{t-135} \cdot \beta + \mu_{t-135} \\ \Delta y &= \Delta F_{t-135} \cdot \beta + \Delta \mu_{t-135} \\ \end{alignat}\]
类似于CAPM
\(r = r_f + \beta_0 (r_{大盘}-r_f) + \mu\)
2.5.2 \(t\)的取值范围
我们先定义什么是半年收益率。 假设股价是\(P_t\),衡量\(t\)时刻,某股票价格为\(P_t\)。 那么它半年后的股价为\(P_{t+ 135}\)。 那么在\(t \in [t,t+135]\)时间内的,收益率为\(r_t=\frac{P_{t+135}-P_t}{P_t}\)。 这个\(r_t\)衡量了在\(t\)时刻,以\(P_t\)价格买入股票,在\(t+135\)时刻卖出股票,的收益率。
我们知道\(t \in [1,488]\),但是同样\(t+135 \in [1,488]\)。 因此\(t \in [1,353]\)。 也就是说,我们计算收益率时,
- 买入价\(P_t\),必须满足\(t \in [1,353]\),同时
- 卖出价\(P_{t+135}\),必须满足\(t \in [1,353]\),即\(t+135 \in [136,488]\)。
综上我们保留\(t \in [1,353]\)的数据。
但是 \(P_t\)我们使用了\(t \in [1,353]\)的价格, \(P_t\)我们使用了\(t \in [136,488]\)的价格。 因此我们没有少用信息。
2.5.3 选择 head
test_y <- seq(20)
test_y
test_y %>% lag(5)
test_y %>% lead(5)2.5.4 选择需要处理\(\Delta\)的因子
2.5.5 计算
2.5.5.1 \(r=\frac{P_{t+1}-P_t}{P_t}\)
full_data_ipt_miss_add_return <-
full_data_ipt_miss_outlier %>%
ungroup() %>%
# 查看缺失值的情况
# filter(code == "stock100052") %>%
# select(rank,code,f58) %>%
# anyNA()
group_by(code) %>%
mutate_at(vars(unstable_vars_list),
function(x){x = (lead(x+1.001,135)-(x+1.001))/(x+1.001)}) %>%
filter(!is.na(close)) %>%
# 探查是否有空值
# anyNA()
# 探查出现在哪个变量,f58
# ungroup() %>%
# summarise_each(funs(sum(is.na(.)))) %>%
# gather() %>%
# arrange(desc(value))
# 探查出现在哪个股票,stock100052
# group_by(code) %>%
# select(rank,code,f58) %>%
# summarise(sum_na = sum(is.na(f58))) %>%
# arrange(desc(sum_na))
# 去表头探查
# 探查出现在哪个rank,124
# group_by(rank) %>%
# select(rank,code,f58) %>%
# summarise(sum_na = sum(is.na(f58))) %>%
# arrange(desc(sum_na))
# 数据本身存在Inf的干扰。
# Inf占比
# ungroup() %>%
# summarise_each(funs(sum(is.infinite(.)))) %>%
# gather() %>%
# arrange(desc(value))
rename(return = close) %>%
ungroup() %>%
select(rank,code,return,everything())
# Here, only close price become return.full_data_ipt_miss_add_return_only <-
full_data_ipt_miss %>%
ungroup() %>%
# 查看缺失值的情况
# filter(code == "stock100052") %>%
# select(rank,code,f58) %>%
# anyNA()
group_by(code) %>%
mutate(
close = (lead(close+1.001,135)-(close+1.001))/(close+1.001)
) %>%
filter(!is.na(close)) %>%
# 探查是否有空值
# anyNA()
# 探查出现在哪个变量,f58
# ungroup() %>%
# summarise_each(funs(sum(is.na(.)))) %>%
# gather() %>%
# arrange(desc(value))
# 探查出现在哪个股票,stock100052
# group_by(code) %>%
# select(rank,code,f58) %>%
# summarise(sum_na = sum(is.na(f58))) %>%
# arrange(desc(sum_na))
# 去表头探查
# 探查出现在哪个rank,124
# group_by(rank) %>%
# select(rank,code,f58) %>%
# summarise(sum_na = sum(is.na(f58))) %>%
# arrange(desc(sum_na))
# 数据本身存在Inf的干扰。
# Inf占比
# ungroup() %>%
# summarise_each(funs(sum(is.infinite(.)))) %>%
# gather() %>%
# arrange(desc(value))
rename(return = close) %>%
ungroup() %>%
select(rank,code,return,everything())2.5.5.2 doing.\(r=\log(\frac{P_{t+1}}{P_t})\)
log_return <- function(x){x = log((lead(x+1.001,135))/(x+1.001))}full_data_ipt_miss_add_return_log <-
full_data_ipt_miss %>%
ungroup() %>%
# 查看缺失值的情况
# filter(code == "stock100052") %>%
# select(rank,code,f58) %>%
# anyNA()
group_by(code) %>%
mutate_at(vars(unstable_vars_list),log_return) %>%
filter(!is.na(close),!is.nan(close)) %>%
# 探查是否有空值
# anyNA()
# 探查出现在哪个变量,f58
# ungroup() %>%
# summarise_each(funs(sum(is.na(.)))) %>%
# gather() %>%
# arrange(desc(value))
# 探查出现在哪个股票,stock100052
# group_by(code) %>%
# select(rank,code,f58) %>%
# summarise(sum_na = sum(is.na(f58))) %>%
# arrange(desc(sum_na))
# 去表头探查
# 探查出现在哪个rank,124
# group_by(rank) %>%
# select(rank,code,f58) %>%
# summarise(sum_na = sum(is.na(f58))) %>%
# arrange(desc(sum_na))
# 数据本身存在Inf的干扰。
# Inf占比
# ungroup() %>%
# summarise_each(funs(sum(is.infinite(.)))) %>%
# gather() %>%
# arrange(desc(value))
rename(return = close) %>%
ungroup() %>%
select(rank,code,return,everything())# Here, only close price become return.
full_data_ipt_miss_add_return_log_only <-
full_data_ipt_miss %>%
ungroup() %>%
# 查看缺失值的情况
# filter(code == "stock100052") %>%
# select(rank,code,f58) %>%
# anyNA()
group_by(code) %>%
mutate(
close = log_return(close)
) %>%
filter(!is.na(close))) %>%
# 探查是否有空值
# anyNA()
# 探查出现在哪个变量,f58
# ungroup() %>%
# summarise_each(funs(sum(is.na(.)))) %>%
# gather() %>%
# arrange(desc(value))
# 探查出现在哪个股票,stock100052
# group_by(code) %>%
# select(rank,code,f58) %>%
# summarise(sum_na = sum(is.na(f58))) %>%
# arrange(desc(sum_na))
# 去表头探查
# 探查出现在哪个rank,124
# group_by(rank) %>%
# select(rank,code,f58) %>%
# summarise(sum_na = sum(is.na(f58))) %>%
# arrange(desc(sum_na))
# 数据本身存在Inf的干扰。
# Inf占比
# ungroup() %>%
# summarise_each(funs(sum(is.infinite(.)))) %>%
# gather() %>%
# arrange(desc(value))
rename(return = close) %>%
ungroup() %>%
select(rank,code,return,everything())2.5.5.3 缺失值再检查
any_miss_infinite <- function(x){
x1 <- x %>% anyNA()
x2 <- x %>%
ungroup() %>%
summarise_each(funs(sum(is.infinite(.)))) %>%
gather() %>%
summarise(sum(value)) %>%
pull()
return(c(x1,x2))
}any_miss_infinite(full_data_ipt_miss_add_return)
# any_miss_infinite(full_data_ipt_miss_add_return_only)
# any_miss_infinite(full_data_ipt_miss_add_return_log)
# any_miss_infinite(full_data_ipt_miss_add_return_log_only)unstable_vars_list有一部分变量出现0的情况,因此在计算\(\delta\)时,会出现\(\frac{x_t-x_{t-135}}{0}\)的情况,因此对这些变量加1\(x \to x+1\)。
但是\(x=-1\)时还是会出现这个问题。
探查数据后,发现都是保留两位小数,因此加\(1.001\)稳了。
数据中存在\(Inf\)的情况,因此计算\(\Delta\)时,会出现Inf/Inf无解的情况,直接fill掉。
2.6 风险分层
full_data_ipt_miss_mu_sigma <-
full_data_ipt_miss_add_return %>%
group_by(code) %>%
summarise(mu = mean(return),sigma = sd(return)) %>%
mutate(tvalue = mu/sigma)
full_data_ipt_miss_mu_sigma_rank_by_3 <-
full_data_ipt_miss_mu_sigma %>%
mutate(group = cut_number(abs(tvalue),3),
group = as.integer(group))
full_data_ipt_miss_mu_sigma_rank_by_3 %>%
group_by(group) %>%
count()full_data_ipt_miss_mu_sigma_rank_by_3 %>%
select(code,group) %>%
write_csv(file.path("data","round4_files","full_data_ipt_miss_mu_sigma_rank_by_3.csv")) 2.7 标准化
dim(full_data_ipt_miss_add_return)
pryr::object_size(full_data_ipt_miss_add_return)part1_index <- 1:round(nrow(full_data_ipt_miss_add_return)/2)
part2_index <- setdiff(1:nrow(full_data_ipt_miss_add_return),part1_index)library(pryr)
object_size(full_data_ipt_miss_add_return)full_data_ipt_miss_add_return %>%
write_csv(file.path("data","round4_files","full_data_ipt_miss_wo_scale.csv"))
# full_data_ipt_miss_add_return[part2_index,] %>%
# write_csv(file.path("data","round4_files","full_data_ipt_miss_wo_scale_part2.csv")) full_data_ipt_miss_wo_scale.csv未标准化数据。
full_data_ipt_miss_add_return %>% anyNA()2.8 PCA构建大盘指数
2.8.1 要求
我们有840个股票,我随机分为三类,每个有280个股票,每个做一个PCA,选择comp1作为大盘指数,因此我们get
三个大盘指数。
为什么要均分三类呢?
这是PCA的算法局限,我们有353期数据,PCA要求被聚的股票数量不能超过353,因此\(\frac{840}{2}=420 > 353\)、\(\frac{840}{3} = 280 < 353\)。
因此分三类才能满足要求。
并且,基本是三因子模型,只要有三个指数,怎么样都是run显著的。
2.8.2 详细内容
我们做一个大盘指数,但是我们不知道确定每个股票在大盘中的权重,我们给予一个假设,越重要的权重越高,那么在无监督的情况下,这和PCA的思路非常类似,其他的还有NMF、t-SNE等,抛砖引玉,先搞PCA。 这里主要参考 Conway and White (2012) 和 Hilpisch (2014) 的思路。
因此当只有一个\(x\)时,SUR理论上肯定可以跑起来了,就用R。
One place where this type of dimensionality reduction is particularly helpful is when dealing with stock market data. (Conway and White 2012)
实际上构建大盘指数的思路就是做降维。
The first new column, will often contain the vast majority of the structure in the entire data set. PCA is particularly effective when the columns in our data set are all strongly correlated. (Conway and White 2012)
这个大盘指数肯定是描述了我们获得股票数据的最重要的结构。 并且PCA对于处理关联性很高的数据是非常有用的,比如股票,同行业同涨同跌。
注意这里使用是股票的价格进行合成而非收益率。
rank_n <- unique(full_data_ipt_miss$rank) %>% length()
rank_n
code_n <- unique(full_data_ipt_miss$code) %>% length()
code_npca_matrix <-
full_data_ipt_miss %>%
select(rank,code,close) %>%
spread(code,close)Error in princomp.default(pca_matrix[-1]) : 'princomp' can only be used with more units than variables
Error in princomp.default(pca_matrix[-1]) : 'princomp' can only be used with more units than variables
意思是说,样本小于变量数量的时候,不能使用princomp,而要使用
prcomp。
pca_model_all <- prcomp(pca_matrix,center = TRUE,scale. = TRUE)
pca_index_table <- predict(pca_model_all) %>% as_tibble()In this summary, the standard deviations tell us how much of the variance in the data set is accounted for by the different principal components. (Conway and White 2012)
如果查看pca_model_1会看到每个comp对数据结构的方差的解释,这里我就不列举了,大家可以尝试下。
PC1的标准差比较大,这里需要进行标准化处理(Conway and White 2012)。
PC1存在负数,不符合股价的假设,无法计算收益率,这里做平移转换。
pca_index_table_add_return <-
pca_index_table %>%
select(PC1) %>%
mutate(PC1 = scale(PC1)+3) %>%
# summarise(
# sum(is.na(PC1)),
# max(PC1),
# min(PC1),
# sum(PC1==-1.001)
# ) %>%
mutate(PC1_return = log((lead(PC1,135))/(PC1))) %>%
filter(!is.na(PC1_return),!is.nan(PC1_return))PC1是大盘指数PC1_return是大盘指数半年收益率
pca_index_table_add_return %>%
write_csv(file.path("data","round4_files","pca_index_table.csv"))因此PCA得到不同股票的权重,非常优秀。
你们可以left_joinPC1_return使用。
2.8.3 CAPM找\(\alpha\)
2.8.3.1 naive \(\alpha\)
alpha_xiaosong_20180419 <-
read_csv(file.path("data","round4_files","alpha_xiaosong_20180419.csv"))alpha_xiaosong_20180419_sum <-
alpha_xiaosong_20180419 %>%
group_by(code_name) %>%
summarise(
r2 = 1 - sum((y_real-y_hat)^2)/sum((y_real-mean(y_real))^2),
alpha = mean(alpha),
y_real_sd = sd(y_real),
y_hat_sd = sd(y_hat)
) %>%
mutate_if(is.double,percent) %>%
mutate(target = alpha/(y_real_sd+y_hat_sd*r2)) %>%
arrange(desc(target))
alpha_xiaosong_20180419_sum %>%
head(50) %>% write_csv(file.path("data","round4_files","alpha_xiaosong_output_20180419.csv"))
alpha_xiaosong_20180419_sum %>%
arrange(desc(alpha)) %>%
head(50) %>% write_csv(file.path("data","round4_files","alpha_xiaosong_output_20180419_02.csv"))
alpha_xiaosong_20180419_sum %>%
select(alpha,target) %>%
gather() %>%
ggplot(aes(x = value,col=key)) +
geom_freqpoly()满足正态分布。
\[\begin{alignat}{2} \text{target: }t &= \frac{\mu}{\sigma}\\ &=\frac{\alpha}{\sigma_y + \sigma_{\hat y} \cdot R^2} \end{alignat}\]
2.8.3.3 \(\alpha, \beta, \text{p value}\)
这里对\(y\)未进行power transformation (见训练模型 training model 使用技巧),仅仅当抛砖引玉。
library(broom)
get_alpha_beta_pvalue <- function(x){
x %>%
select(rank,code,return) %>%
left_join(
pca_index_table_add_return %>%
select(PC1_return) %>%
add_column(
rank = x %>% distinct(rank) %>% .$rank
)
,by = "rank"
) %>%
# filter(code %in% c("stock100000","stock100003")) %>%
# 小数据测试函数
group_by(code) %>%
nest() %>%
mutate(model = map(.x = data, .f = ~ lm(return ~ PC1_return, data = .x)),
output = map(.x = model, .f = ~ tidy(.))) %>%
select(code,output) %>%
unnest() %>%
select(code, term, estimate, p.value) %>%
gather(metric,value,estimate:p.value) %>%
unite("type",c("term","metric")) %>%
spread(type,value) %>%
rename_all(
funs(
str_replace_all(.,"\\(Intercept\\)","alpha") %>%
str_replace_all(.,"estimate","value") %>%
str_replace_all(.,"PC1_return","beta")
)
)
}.f = ~ lm(return ~ PC1_return, data = .x)
这里批量跑方程的方法可以多参考 Wickham and Grolemund (2017 Chapter 20, pp. 402)。
data_alpha_beta_pvalue <- get_alpha_beta_pvalue(full_data_ipt_miss_add_return)data_alpha_beta_pvalue %>%
select(alpha_value:beta_p.value) %>%
summarise_all(funs(min(.),max(.))) %>%
gather()\(\alpha, \beta \in [-1,1.04]\)不利于我们分析,我们统一平移2个单位,使得它们\(\geq 1\)。 现在我们需要p value越小越好,\((1-\text{p value)}\)衡量了我们对\(\alpha\)和\(\beta\)的信任程度, 我们对\(alpha\)和\(\beta\)进行如下修改,参考Cobb-Douglas函数 (Nicholson and Snyder 2011)。
\[\alpha^* = \alpha^{1-\text{p value}}\] \[\beta^* = \beta^{1-\text{p value}}\]
data_alpha_beta_pvalue_edited <-
data_alpha_beta_pvalue %>%
mutate(
alpha = map2_dbl(.x = alpha_value,.y = alpha_p.value,.f = ~ (.x+2)^(1-.y)),
beta = map2_dbl(.x = beta_value, .y = beta_p.value, .f = ~ (.x+2)^(1-.y))
) %>%
# summarise(
# sum(alpha_value > 0 & alpha < 0),
# sum(beta_value > 0 & beta < 0)
# # 验证符号是否有错
# )
select(code,alpha,beta)alpha_beta_pvalue_best_sample <-
data_frame(best_n = 20:50) %>%
mutate(data = map(
.x = best_n,
.f = function(n){best_target(data_alpha_beta_pvalue_edited,n)}
))alpha_beta_pvalue_best_sample %>%
mutate(target = map(.x = data,
.f = function(x){
x %>%
summarise(
alpha = mean(alpha),
beta = mean(beta),
target = alpha/abs(beta)
) %>%
select(target)
})) %>%
select(best_n,target) %>%
unnest() %>%
arrange(desc(target)) %>% head()alpha_beta_pvalue_best_sample %>%
filter(best_n == 23) %>%
select(data) %>%
unnest() %>%
write_csv(
file.path("data","round4_files","alpha_beta_pvalue_best_sample.csv"))2.8.3.4 使用更加复杂的模型
替换原来的OLS为
lassobiglm
2.9 增加大盘index close
逻辑太粗暴,T了。
full_data_ipt_miss_add_return <-
full_data_ipt_miss_add_return %>%
group_by(rank) %>%
mutate(index = mean(return),
index_sq = index^2)2.10 y滞后项作为自变量
单规则厉害,正说明了y要做自变量。
这里增加15次lag滞后项,逐日。
未剔除缺失值,方便大家可以选择少量lag滞后项,而不是武断减少1.2610^{4}个自由度。
library(data.table)
data_lag_y_15 <-
full_data_ipt_miss_add_return %>%
ungroup() %>%
group_by(code) %>%
do(data.frame(.,
setNames(
shift(
.$return, 1:15),
paste(
"return_lag",
seq(1:15),
sep="_")))) %>%
select(rank,code,contains("return"))2.10.1 利用tidyquant,方法二(Li 2018)。
library(tidyquant)
library(tibbletime)
data_lag_y_15_ver2 <-
full_data_ipt_miss_add_return %>%
filter(code %in% full_data_ipt_miss_add_return$code[1:3]) %>% # 用小样本进行检验
select(rank,code,return) %>%
mutate(rank = as.Date("2018-01-01")+rank) %>%
as_tbl_time(index = rank) %>%
tq_mutate(
select = return,
mutate_fun = lag.xts,
k = 1:15,
col_rename = paste0("return_lag_",1:15)
)
data_lag_y_15_ver2 %>%
select(-rank) %>% as.data.frame() %>%
setequal(
data_lag_y_15 %>%
filter(code %in% data_lag_y_15$code[1:3]) %>% # 用小样本进行检验
select(-rank) %>% as.data.frame()
)2.10.2 检查批量成功进行
data_lag_y_15 %>%
summarise_all(funs(sum(is.na(.)))) %>%
head(10)data_lag_y_15 %>%
write_csv(file.path("data","round4_files","data_lag_y_15.csv"))2.11 建立x滞后项
\(\Delta x\)效果好,但是选\(x\)。 我们的目的是任意股票在\(t=488+135\)时,预测\(\hat r_{488+135}\),如果预测足够准,选择最好的20-50个\(\hat r_{488+135}\)。
这里\(r_{488+135} = \frac{P_{488+135}-P_{488}}{P_{488}}\),这里\(P_{488}\)我们是已知的。 因此我们实际上是预测\(P_{488+135}\)。
2.11.1 使用\(\Delta x\)进行预测
\[P_{488+135} \sim r_{488+135} \sim \Delta x\]
这里\(x\)最大取到488, 因此, \(\Delta x = \frac{x_{488}-x_{488-135}}{x_{488-135}} \sim x_{488} + x_{488-135}\)。 因此我们实际上是用\(P_{488+135} \sim x_{488} + x_{488-135}\)进行预测。
2.11.2 使用\(x\)进行预测
\[P_{488+135} \sim r_{488+135} \sim x\]
这里\(x\)最大取到488, 因此, \(x = x_{488}\)。 因此我们实际上是用\(P_{488+135} \sim x_{488}\)进行预测。
这也说明了,为什么使用\(x\)进行预测效果差一些,因为自变量少了一个动量\(x_{488-135}\),这个好办,我们可以增加\(x_{t-p}\)来完成好了。
因此我们选择\(x\)这样我们可以有更大的自由空间。
这里我会做出\(x_{t-1},\cdots,x_{t-15}\)给大家使用,这样大家就不用受制于\(\Delta x\)。
2.11.3 代码
因为变量很多,如果全部做lag(1:15),数据表太大,会产生1.2610^{4}个新变量,没有意义,因为我们的数据集不够。
因此根据之前的随机森林结果,取前十importances高的变量做lag(1:15)。
f6, f12, f29, f49, f50, f51, f54, f55, f82, f87。
imp10_vars <-
full_data_ipt_miss_add_return %>%
select(rank,code,f6, f12, f29, f49, f50, f51, f54, f55, f82, f87)dim(imp10_vars)library(data.table)
imp10_vars_w_lag_15 <-
imp10_vars %>%
group_by(code) %>%
do(data.frame(.,
setNames(shift(.$f6, 1:15), paste("f6_lag",seq(1:15))),
setNames(shift(.$f12, 1:15), paste("f12_lag",seq(1:15))),
setNames(shift(.$f29, 1:15), paste("f29_lag",seq(1:15))),
setNames(shift(.$f49, 1:15), paste("f49_lag",seq(1:15))),
setNames(shift(.$f50, 1:15), paste("f50_lag",seq(1:15))),
setNames(shift(.$f51, 1:15), paste("f51_lag",seq(1:15))),
setNames(shift(.$f54, 1:15), paste("f52_lag",seq(1:15))),
setNames(shift(.$f55, 1:15), paste("f55_lag",seq(1:15))),
setNames(shift(.$f82, 1:15), paste("f82_lag",seq(1:15))),
setNames(shift(.$f87, 1:15), paste("f87_lag",seq(1:15)))
))library(pryr)
object_size(imp10_vars_w_lag_15)names(imp10_vars_w_lag_15) %>% as.tibble()imp10_vars_w_lag_15_partition_index <-
data.table(index = 1:4,b = 1:nrow(imp10_vars_w_lag_15)) %>%
select(index)imp10_vars_w_lag_15_partition <-
bind_cols(imp10_vars_w_lag_15,imp10_vars_w_lag_15_partition_index) %>%
select(index,everything())object_size(imp10_vars_w_lag_15_partition)imp10_vars_w_lag_15_partition %>%
write_csv(file.path("data","round4_files","imp10_vars_w_lag_15.csv"))
# imp10_vars_w_lag_15_partition %>%
# filter(index == 1 | index == 2) %>%
# write_csv(file.path("data","round4_files","imp10_vars_w_lag_15_part1.csv"))
# imp10_vars_w_lag_15_partition %>%
# filter(index == 3 | index == 4) %>%
# write_csv(file.path("data","round4_files","imp10_vars_w_lag_15_part2.csv"))2.12 行业分类
Hierarchical clustering
行业股票存在同涨同跌趋势,因此如果在\(t \in [1,488]\)期间,股票的涨跌情况大多一致,那么可以认为这是一类股票,大概率属于同行业。
我们使用hclust()函数进行聚类。
cluster_data <-
full_data_ipt_miss %>%
select(code,rank,close) %>%
group_by(code) %>%
mutate(daily_return = (close-lag(close))/lag(close)) %>%
filter(!is.na(daily_return)) %>%
select(code,rank,daily_return) %>%
mutate(daily_return = ifelse(daily_return > 0, 1,0)) %>%
spread(rank,daily_return)现在不同code之间,rank数量是不一致的,我们只考虑股票都有的情况下,股票之间的相关性。
hclust.out <- hclust(dist(as.matrix(cluster_data[-1])))plot(hclust.out)cluster_tag <- cutree(hclust.out,k = 5)
cluster_tag %>% table()cluster_data %>%
select(code) %>%
add_column(hclus_tag = cluster_tag) %>%
write_csv(file.path("data","round4_files","hclus_tag.csv"))后续,在这基础上做同行业的PCA,做指数,最后看alpha。
2.13 指标构建思想
2.13.1 收益率>需要normalized和log化
数据存在右偏,log化后,减少偏度。 要normalize的处理,保证数据更加符合标准正态分布。
log returns are additive but __scaled percent returns __aren’t. In other words, the five-day log return is the sum of the five one-day log returns. This is often computationally handy. (Schutt and O’Neil 2013)
并且使用log return是因为其具备可加性。
\[\log \frac{P_{t}}{P_{t-p}} = \prod_{i=0}^{p-1}\log \frac{P_{t-i}}{P_{t-i-1}}\]
其次,其增减对称。
log(1-0.5)
log(1+1)之间转换很近似。
\[\begin{alignat}{2} \log(x) &= \sum_{n}\frac{(x-1)^n}{n} = (x-1) - \frac{(x-1)^2}{2} + \cdots\\ \text{log returns}&=\text{scaled percent returns}-\frac{(x-1)^2}{2} + \cdots\\ \end{alignat}\]
data_frame(x = seq(0.01,5,by = 0.01)) %>%
mutate(log_x = log(x),
x_1 = x-1) %>%
gather(key,value,-x) %>%
ggplot(aes(x = x,y=value,col=key)) +
geom_line()在\(x=1\)处非常近似。 这里的x = \(\frac{P_t}{P_{t-1}}\)
2.13.1.1 log return的近似处理,使用泰勒公式
定义
\[\begin{cases} a_t = \frac{A_{t+1}}{A_{t}}-1\\ b_t = \frac{B_{t+1}}{B_{t}}-1\\ \log A_{t+1} = \gamma_0 + \gamma_1 \log B_{t+1} + \mu_{t+1} \\ \log A_{t} = \gamma_0 + \gamma_1 \log B_{t} + \mu_{t} \end{cases} \\ \begin{alignat}{2} \to\log A_{t+1} -\log A_{t} &= \gamma_1 (\log B_{t+1} - \log B_{t}) + ( \mu_{t+1} - \mu_{t}) \\ \log A_{t+1} -\log A_{t} &= \gamma_1 (\log B_{t+1} - \log B_{t}) \\ \log ((1+a)A_{t}) -\log A_{t} &= \gamma_1 (\log ((1+b)B_{t}) - \log B_{t}) \\ \log (1+a) + \log A_{t} -\log A_{t} &= \gamma_1 (\log ((1+b) + \log B_{t}- \log B_{t}) \\ \log (1+a) &= \gamma_1 \log ((1+b) \\ \frac{\log (1+a)}{ \log ((1+b)} &= \gamma_1 \\ \frac{a}{b} &\approx \gamma_1 \\ \frac{a \times 100 \%}{b \times 100 \%} &\approx \gamma_1 \\ \end{alignat} \]
2.13.2 风险>权重衰减
风险度量我们可以直接使用标准差,但是我们想尽可能的表现距离近的影响大于距离远的影响。 Exponential Downweighting(Schutt and O’Neil 2013)是解决办法之一。 这里类似于现金流预测,加入一个折现率\(s\)。
\[\begin{alignat}{2} \text{Var}_{old} &= \frac{\sum_i s^i \cdot r_i^2}{\sum_i s^i}\\ &=\frac{\sum_i s^i \cdot r_i^2}{\frac{1}{1-s}}\\ &=(1-s)\sum_i s^i \cdot r_i^2\\ \end{alignat}\]
\[\text{Var}_{new} = s\text{Var}_{old} + (1-s)r_0^2\]
\(r_0\)表示当期的收益率,假设\(E(r_0)=0\),因此\(\text{Var}(r_0) = E(r_0-E(r_0))^2=r_0^2\)
这个\(s\)一般可以用0\(.97\)等近似于但小于1的数假设。
2.13.3 使用先验信息
类似于AR模型,我们使用\(y_{t-p}\)预测\(y_t\),但是这一次我们将其写入损失函数中。(Schutt and O’Neil 2013)
\[\begin{alignat}{2} L &= \sigma(y-\hat y) + \gamma(\beta) + \rho(\beta_j-\beta_{j+1})\\ &\begin{cases} \sigma(y-\hat y) &\sim \frac{1}{N}\sum_i (y-x\beta)^2 &\sim \text{RMSE}\\ \gamma(\beta) &\sim \sum_j(\beta)^2 &\sim \text{正则化}\\ \rho(\beta_j-\beta_{j+1}) &\sim \sum_j(\beta_j-\beta_{j+1})^2 &\sim \text{smoothing}\\ \end{cases} \end{alignat}\]
adjacent coefficients should be not too different from each other. (Schutt and O’Neil 2013)
\(\rho(\beta_j-\beta_{j+1})\)要求我们可以用滞后项去预测,但是中间的自相关系数不能跳变太大,否则不符合我们的直觉。 但是这样构建一个函数处理,但是我目前没看到包直接可以调用这种损失函数。
2.14 时间选择解释
按照 DataCastle小运营 (2018) 官方解释,488天,一定要损失\(\frac{1}{4}\)数据,具体见链接(http://u6.gg/dqv2b)。
D4这一时间段的数据是必须损失的,
而且损失的是D4,非D1,因此是损失靠后,而非靠前的数据。
窗口滚动预测(DataCastle小运营 2018)中,官方认可了D2和D4都作为 预测集,我推测,不一定是最后的数据一定是就是最好的,而是D2和D4都可以作为预测集,数据表现为每年的下半年数据。
我觉得是符合逻辑的,因为我们注意看,如果我们把488天分开来看,第一年是大涨后跌又大涨的,然而第二年似乎比较平缓,也许这两个下半年都是一个周期性的表现,说不准,因此预测未来半年收益率,测试集选D2和D4,比较合理。
这里的向量合并参考 Wickham (2014)。
pca_index_table_add_return <- read_csv(file.path("data","round4_files","pca_index_table.csv"))
pca_index_table_add_return %>%
select(PC1) %>%
mutate(rank = 1:nrow(.),
type =
c(
rep(1,times = 244),
rep(2,times = 353-244))
) %>%
ggplot(aes(x = rank, y = PC1, col=as.factor(type))) +
geom_line()麻婆豆腐的python代码,蛮有意思的,我有空看看啥意思。
2.15 arima预测半年收益率
library(tibbletime)
library(forecast)
arima_fun <- function(data){
auto.arima(
data %>%
# full_data_ipt_miss_add_return %>%
# filter(code %in% unique(full_data_ipt_miss_add_return$code)[1:3]) %>% # 用小样本进行检验
.$return
) %>%
forecast(.,h=488/4) %>%
as.data.frame() %>%
tail(1) %>%
mutate(sd = (`Hi 95`-`Lo 95`)/3) %>%
rename(avg = `Point Forecast`) %>%
select(avg,sd) %>%
gather()
}arima_result <-
full_data_ipt_miss_add_return %>%
# filter(code %in% unique(full_data_ipt_miss_add_return$code)[1:3]) %>% # 用小样本进行检验
select(rank,code,return) %>%
mutate(rank = lubridate::as_date(rank)) %>%
as_tbl_time(index = rank) %>%
group_by(code) %>%
nest() %>%
mutate(model = map(data, arima_fun)) %>%
select(code,model) %>%
unnest() %>%
spread(key,value) %>%
mutate(zscore = avg/sd) %>%
arrange(desc(zscore))arima_result %>%
head(20) %>%
write_csv(file.path("data","round4_files","arima_by_target.csv"))
arima_result %>%
arrange(desc(avg)) %>%
head(20) %>%
write_csv(file.path("data","round4_files","arima_by_avg.csv"))2.16 回传数据的说明
假设武神和晓松都做了两个模型,分别是
\[\begin{cases} \text{晓松: } r_{i,t;晓松} = \beta_0 + \beta_1 r_{t}^{PC1} + \mu_{i,t}\\ \text{武神: } r_{i,t;武神} = f(x) + \epsilon \end{cases}\\ \xrightarrow{都进行预测} \begin{cases} \text{晓松: } r_{i,t;晓松} = \hat \beta_0 + \hat \beta_1 r_{t}^{PC1}\\ \text{武神: } r_{i,t;武神} = \hat f(x) \end{cases}\\ \xrightarrow{回传数据进行新的预测} \begin{cases} \text{晓松: } r_{i,t;晓松} = \beta_0 + \beta_1 r_{t}^{PC1} + \beta_2 \hat r_{i,t;武神} + \mu_{i,t}\\ \text{武神: } r_{i,t;武神} = f(x,\hat r_{i,t;晓松}) + \epsilon \end{cases} \]
因此可知,以晓松的模型为例, 对827只股票进行预测,时期数为353期,这就是时期的意思。
\[\begin{cases} i = 1,\cdots,827\\ t = 1,\cdots,353 \end{cases}\]
因此回传的数据,也必须是\(827个股票 \times 353期\)用于进行新的模型训练。
2.17 分类思想补充
戴军, 黄志文, and 葛新元 (2010, 5),1 彭堃 (2017) 将选股问题转化为分类问题,
- 如果股票当期收益率超过大盘指数收益率,记为\(y=1\)
- 如果股票当期收益率未超过大盘指数收益率,记为\(y=0\)
这里有个好处是,\(y=1\)和\(y=0\)的占比相当,可以防止样本不平衡的问题。
2.18 实验设计思路
之前在488天选择时期上,大家一直有疑问,今天我想了一个应该是十分清楚的表达方式了,现在分享下。
2.18.1 样本理解
以一个股票为例
\[\begin{alignat}{2} P_1,\cdots,P_{488} &\xrightarrow{预测,h=135,表示半年} P_{488+h}\\ \begin{cases} P_1, P_{136} &\to r_1\\ \vdots & \vdots\\ P_{353}, P_{488} &\to r_1\\ \end{cases} &\xrightarrow{预测,h=135,表示半年} \begin{cases} P_{353+1}, P_{488+1} &\to r_{353+1}\\ \vdots & \vdots\\ P_{353+135}, P_{488+135} &\to r_{353+135}\\ \end{cases} \end{alignat}\]
实际上我们真正需要预测的是
\[P_{353+135}, P_{488+135} \to r_{353+135}\]
- 因为\(P_{488+135}\)未知,所以\(r_{353+135}\)未知,所以这才是我们的工作。
- 注意这里我定义,用\(P_{353}\)和\(P_{488}\)计算出\(r_{353}\),这里的\(353\)是没有意义,我只是这样表示,为了和\(P_{353}\)统一。
- 因此,我们没必要去争论选择\(1 \sim 353\)还是\(136 \sim 488\),因为我们指的是同一个意思。
2.18.2 实验设计
下面是我思考的构建模型的方式。
现在我们已知的\(r_t\)中,\(t \in [1,353]\)是没有争议的了,我们平分三份,
- \(t \in [1,118]\),train组,用于训练,
- \(t \in [119,236]\),validation组,用于验证
- \(t \in [237,353]\),test组,用于评估
边界118和237的选取,可以修改的,这个不是规定的。
例如现在晓松和武神的模型,一个是\(\alpha\)策略、一个是分类问题,
可以尝试
- 用train组训练,
- 用validation组验证,防止过拟合
- 用test组的真实数据和预测数据进行比较
如果在test组上表现好,那么认为这个策略、或者处理问题的方向是对的,下一步我们需要换模型的参数和训练集。 因为我们这里的模型只能说在\(t \in [237,353]\)上预测的好,但是我们需要预测的是\(t = 488\)这一期的\(r\)或者\(r\)的排名。
因此我们确定这次实验用分类模型,那么里面的参数肯定需要修改, 其次,train组和validation组需要换,我们可以用\(t \in [237,353]\)的样本作为训练集,因为我们离预测那天越近,理论上训练集效果越好。
然后,我们只预测\(r_488\),或者为了求一点稳定性,预测\(r_{488}\)最近10天的数据,求平均。 最后选出最优的股票。
2.19 Y变量定义为半年的Sharpe Ratio
狗熊会 (2018) 对基金选择进行的研究,我觉得和选股的方向有一定的相似性。 狗熊会 (2018) 的y变量定义为 Sharpe Ratio 。 我考虑,我们也可以用半年 Sharpe Ratio 作为Y变量。
我们之前Y变量的口径是个股半年收益率,但是我们在最后选股的时候是使用Sharpe Ratio的高低考虑的。
\[SR = \frac{E(R)}{\sigma_R}\]
我们的损失函数是\(\min \sum (r - \hat r)^2\),但是目标函数是\(\max \frac{\bar R_{20股}}{\sigma_{20股}}\)。 因此这有点矛盾,我建议,将y变量直接替换成Sharpe Ratio,实现统一,最优化问题从
\[ \begin{equation} \min \sum (r - \hat r)^2\\ \mathrm{s.t. \max \frac{\bar R_{20股}}{\sigma_{20股}}}\\ \end{equation} \] 变成
\[\begin{equation} \min \sum (\frac{r}{\sigma_{半年}} - \hat{SR})^2\\ \mathrm{s.t. \max \frac{\bar R_{20股}}{\sigma_{20股}}}\\ \end{equation}\]
我总结了下这个方向下一步可以做哪些地方,
- 这里的\(\sigma\)为滚动的半年的日标准差。这样我们可以充分的使用我们的数据。
- 其次,因为y变量选取了Sharpe Ratio,我们最后的选股,也表达了稳定性和收益率的均衡。
- 这个也可以做分类问题,比如最高的50个股票的Sharpe Ratio,或者跑赢大盘Sharpe Ratio的股票。
这里需要滚动处理,我周六可以弄出来数据,我们可以讨论一下,如果可做, 晓松和武神你们可以尝试做一下?
2.20 金工报告阅读
- 林晓明, 陈烨, and 李子钰 (2018, 10)将单只股票单时期作为一个样本,因此不考虑时间先后顺序的影响。
- y变量的定义与本文的定义相似,选取的下个时期收益情况。这使得每个\(x\)变量都是历史信息,不是与\(y\)同时发生的,这是我们目前的做法。(林晓明, 陈烨, and 李子钰 2018, 10)
- y变量的定义为
- 下个时期收益前30%, y = 1
- 下个时期收益后30%, y = 0
- 因此中间的40%的样本是不讨论的。这点我觉得我们按照实际情况,可以不借鉴。(林晓明, 陈烨, and 李子钰 2018, 10)
- 林晓明, 陈烨, and 李子钰 (2018, 12)做了长短期模型,我们可以借鉴。
- 在验证集上,他们只使用两期,而非我们常规操作2:8分。
- 训练集上,短期用6个月样本,长期用72个月样本,模型训练好后,都进行集成,试图表现长短期效果。
- \(x\)变量都做了中位数去极值处理、标准化处理,这个我后期可以加入。(林晓明, 陈烨, and 李子钰 2018, 10)
- 如果下个交易日停牌的股票,本期数据剔除。(林晓明, 陈烨, and 李子钰 2018, 10)
- 上市只有3个月内的股票,该股票所有数据剔除。(林晓明, 陈烨, and 李子钰 2018, 10)
集成算法中, 林晓明, 陈烨, and 李子钰 (2018, 7=6) 分两层计算。
- 第一层是树模型、神经网络、SVM等算法,希望抓住数据的非线性结构。
- 第二层使用逻辑回归类的线性模型。
- 第一层的算法间相关性越低,说明集成后的第二层模型更稳定,泛化能力更强。
- 因此可以考虑长短期模型,使得训练集不同,回传预测值\(\hat y\)也不同,提高第二层的模型稳定性。
- 由于要检测第一层算法间的相关性低,因此逻辑回归是比较好能够适用这种情况的模型,如果回传的\(\beta\)不高,但是算法本身预测值高,可以判断算法间有很高相似性,触发共线性问题。
我觉得 林晓明, 陈烨, and 李子钰 (2018) 思路比较清晰,我们可以直接借鉴试试。
2.21 组合\(\beta\)逻辑 \(\frac{\alpha_{\mathrm{portfolio}}}{\beta_{\mathrm{portfolio}}}\)
\[{\beta}_{\mathrm{portfolio}} = \frac{\mathrm{Cov}(R_p, R_m)}{\sigma_m} \]
\(\beta\)的计算是算数平均 (Regenstein 2018),因此\(\alpha\)的计算也是算数平均。 因此直接用可以
\[\frac{\alpha_{\mathrm{portfolio}}}{\beta_{\mathrm{portfolio}}}\]
来作为评价标准即可。
3 模型方法
3.1 naive group
3.1.1 naive
我是相当于每个rank,选出半年收益率最高的五十个,最后汇总起来,哪个股票出现频次越多,就越容易选上。但是最后我只选前30,这个数字只是好奇的选的。
\[\begin{alignat}{2} \forall i: \frac{P_{488+135}^{i}-P_{488}^{i}}{P_{488}^{i}} = r_{488}^{i} &\sim f^{i}(r_1,\cdots,r_{353})\\ &\sim \sum_{j=1}^{353}\mathcal I(r_j^i \text{ is top 50}) = \\ &\to \text{choose top 30} \hat f^{i}(r_1,\cdots,r_{353}) \end{alignat}\]
因此这里实际上把回归问题转化为一个分类问题\(\mathcal I(r_j^i \text{ is top 50})\),但是也还是只用了\(r\)的信息,没有使用\(x\),正说明了滞后项、\(r\)信息很重要。
\[\mathcal I(y) = \begin{cases} 1&\text{, y is true}\\ 0&\text{, y is false}\\ \end{cases}\]
all_data %>%
# names()
select(1:3) %>%
group_by(code) %>%
mutate(close_lag = lag(close,135)) %>%
filter(!is.na(close_lag)) %>%
mutate(return = (close-close_lag)/close_lag*100) %>%
ungroup() %>%
# distinct(rank)
group_by(rank) %>%
top_n(50,return) %>%
ungroup() %>%
group_by(code) %>%
count() %>%
arrange(desc(n)) %>%
ungroup() %>%
top_n(30,n) %>%
write_csv(file.path("data","round4_files","naive_30.csv")) %>%
select(everything())3.1.2 naive 2.0
full_data_ipt_miss %>%
group_by(code) %>%
mutate(close_lag = lag(close,135)) %>%
filter(!is.na(close_lag)) %>%
mutate(return = (close-close_lag)/close_lag*100) %>%
ungroup() %>%
# distinct(rank)
group_by(rank) %>%
top_n(50,return) %>%
ungroup() %>%
group_by(code) %>%
count() %>%
arrange(desc(n)) %>%
ungroup() %>%
top_n(30,n) %>%
write_csv(file.path("data","round4_files","naive_30_2.0.csv")) %>%
select(everything()) 3.1.3 naive 3.0
library(TTR)a <- seq(20)
a
SMA(a,6)移动平均: 对的,相当于我做了稳定性处理,也就是说这个处理过的收益率是吸收了风险的。
unique_rank <-
all_data %>%
group_by(code) %>%
count() %>%
arrange(n) %>%
filter(n > 158)
all_data %>%
filter(code %in% unique_rank$code) %>%
group_by(code) %>%
mutate(close_lag = lag(close,135)) %>%
filter(!is.na(close_lag)) %>%
mutate(return = (close-close_lag)/close_lag*100) %>%
mutate(return_SMA_7 = SMA(return,7)) %>%
select(rank,code,return,return_SMA_7) %>%
filter(!is.na(return_SMA_7)) %>%
ungroup() %>%
# distinct(rank)
group_by(rank) %>%
top_n(50,return_SMA_7) %>%
ungroup() %>%
group_by(code) %>%
count() %>%
arrange(desc(n)) %>%
ungroup() %>%
top_n(30,n) %>%
write_csv(file.path("data","round4_files","naive_30_3.0.csv")) %>%
select(everything()) 3.1.4 naive 4.0
我们发现在naive的答案中,第一个是最naive的,但是还是非常坚挺的。
我觉得可以控制i和j两个top_n的参数或许得到提升,这是一个最优化的问题,
最后感觉的确得到了提升。
valid_avg_return <-
full_data_ipt_miss_add_return %>%
filter(rank > 117,rank < 235) %>%
select(rank,code,return) %>%
group_by(code) %>%
summarise(return = mean(return))choose_best_boundary <- function(i,j){
all_data %>%
# names()
select(1:3) %>%
group_by(code) %>%
mutate(close_lag = lag(close,135)) %>%
filter(!is.na(close_lag)) %>%
mutate(return = (close-close_lag)/close_lag*100) %>%
ungroup() %>%
# distinct(rank)
group_by(rank) %>%
top_n(i,return) %>%
ungroup() %>%
group_by(code) %>%
count() %>%
arrange(desc(n)) %>%
ungroup() %>%
top_n(j,n) %>%
left_join(valid_avg_return,by="code") %>%
summarise(mean(return)) %>%
pull()
}grid_boundary <-
expand.grid(i = seq(20,25,1), j = seq(20,25,1)) %>%
mutate(return = map2_dbl(i,j,choose_best_boundary))grid_boundary %>%
arrange(desc(return))all_data %>%
# names()
select(1:3) %>%
group_by(code) %>%
mutate(close_lag = lag(close,135)) %>%
filter(!is.na(close_lag)) %>%
mutate(return = (close-close_lag)/close_lag*100) %>%
ungroup() %>%
# distinct(rank)
group_by(rank) %>%
top_n(21,return) %>%
ungroup() %>%
group_by(code) %>%
count() %>%
arrange(desc(n)) %>%
ungroup() %>%
top_n(21,n) %>%
write_csv(file.path("data","round4_files","naive_30_4.0.csv")) %>%
select(everything())3.2 \(\mu, \sigma\)
full_data_ipt_miss_mu_sigma %>%
arrange(desc(tvalue)) %>%
head(30) %>%
write_csv(file.path("data","round4_files","mu_sigma_30.csv"))3.3 linear regression
3.3.1 SUR close
相比较于面板数据的模型,考虑了个体效应,SUR还允许了不同个体拥有不同的\(\beta\)。
Unlike the panel data models considered in the preceding section, which permit only individual-specific intercepts, the SUR model also allows for individual-specific slopes. (Kleiber and Zeileis 2008)
library(systemfit)
code_choice <- full_data_ipt_miss_wo_scale %>% distinct(code) %>% .$code %>% head(50)
test_SUR <- subset(full_data_ipt_miss_wo_scale, code %in% code_choice)
library(plm)
test_SUR_plm <- plm.data(test_SUR, c("code","rank"))
test_SUR_model <- systemfit(return ~ f1, method = "SUR", data = test_SUR_plm)Error in LU.dgC(a) : cs_lu(A) failed: near-singular A (or out of memory)
library(broom)
for (i in seq(length(code_choice))){
summary(test_SUR_model)$eq[[i]]$coefficients %>% as.data.frame() %>% print()
}3.3.2 OLS
3.3.2.1 get \(\Delta x\)
3.3.2.1.1 控制id和f的数量
code_limit <-
full_data_ipt_miss_add_return %>%
ungroup() %>%
distinct(code) %>%
.$code %>%
head(2+1000)
f_limit <-
names(full_data_ipt_miss_add_return) %>%
str_subset("code|f\\d{1,2}|return|index") %>%
head(2+1000)3.3.2.2 get x close
我想过是不是因为\(\Delta x\)和\(x\)不一样导致的,但是我用biglm作为例子试过了,发现并非如此。
这个猜想无效的。
这也解释了为什么xgboost效果也不行,因为\(x\)是trivial的。
3.3.2.3 modeling
model_text <-
paste("return",
f_limit %>% str_subset("f|index") %>% paste(collapse = "+"),
sep = "~")dataset_big_ols <- function(x){
x %>%
select(f_limit) %>%
filter(code %in% code_limit)
}
test_big_OLS <- dataset_big_ols(full_data_ipt_miss_add_return)
test_big_OLS_return_only <- dataset_big_ols(full_data_ipt_miss_add_return_only)
library(biganalytics)
library(broom)
get_ols_output <- function(x){
x %>%
group_by(code) %>%
nest() %>%
mutate(model = map(data,
function(df){biglm(as.formula(model_text), data = df) %>%
# function(df){biglm(return ~.,
# data = df %>%
# select_if(function(y){n_distinct(y)>1})
tidy()})) %>%
select(code,model) %>%
unnest() %>%
filter(term == "(Intercept)") %>%
arrange(desc(estimate))
}
ols_alpha_output <- get_ols_output(test_big_OLS)
# ols_alpha_output_return_only <- get_ols_output(test_big_OLS_return_only)select_if(function(y){n_distinct(y)>1})
这个地方的报错没有解决,
Error in mutate_impl(.data, dots) : variable 'y' not found
原因是这个变量不能识别。
Error in mutate_impl(.data, dots) : Evaluation error: NA/NaN/Inf in foreign function call (arg 3).
ols_alpha_output_return_onlyrun不出来。
3.3.2.4 perf
library(broom)
get_ols_perf <- function(x){
x %>%
group_by(code) %>%
nest() %>%
mutate(model = map(data,
function(df){biglm(as.formula(model_text), data = df) %>%
glance()})) %>%
select(code,model) %>%
unnest()
}
ols_alpha_perf <- get_ols_perf(test_big_OLS)
ols_alpha_perf_return_only <- get_ols_perf(test_big_OLS_return_only)ols_alpha_perf %>%
select(code,r.squared) %>%
rename(rsq = r.squared) %>%
left_join(
ols_alpha_perf_return_only %>%
select(code,r.squared) %>%
rename(rsq_only = r.squared),
by = "code"
) %>%
mutate(delta_rsq = rsq-rsq_only) %>%
ggplot(aes(x = delta_rsq)) +
geom_freqpoly()\(\Delta x\)效果明显强于\(x\),比较每个code的\(R^2\)。
但是我们无法get \(t = 488\)这天的\(\Delta x\)只有\(x\)。
但是实际上,我们拿到的\(\Delta x\)也包含了\(x_{488}\)和\(x_{488-135}\)的信息,没差,可能就是说\(\Delta x\)是相减得到的,损失了一部分信息,但是如果这个剪完就是0了,说明这个变量很稳定,对y的预测效果很少啊。
所以还是follow\(\Delta x\)的思路。
ols_alpha_output %>%
filter(p.value < 0.05) %>%
top_n(30,estimate) %>%
write_csv("biglm_alpha_top_30.csv")
ols_alpha_output_return_only %>%
filter(p.value < 0.05) %>%
top_n(30,estimate) %>%
write_csv("biglm_alpha_top_30_return_only.csv")SUR模型在Python和R上都失败了,这里使用biglm建立各公司之间独立的OLS回归,找\(\alpha\)最大的前30.
biglm_alpha_top_30.csv
数据下载地址,
https://raw.githubusercontent.com/JiaxiangBU/picbackup/master/biglm_alpha_top_30.csv
3.4 加入\({\hat y}^2\)
考虑平方项
3.5 xgboost
3.5.1 import data
full_data_ipt_miss_wo_scale <- full_data_ipt_miss_add_returndim(full_data_ipt_miss_wo_scale)
dim(three_index_table)3.5.2 train test split
full_data_ipt_miss_wo_scale_add_three <-
full_data_ipt_miss_wo_scale %>%
left_join(three_index_table,by="rank")
xgboost_train <- full_data_ipt_miss_wo_scale_add_three %>% filter(rank <= 117)
xgboost_valid <- full_data_ipt_miss_wo_scale_add_three %>%
filter(rank > 117, rank <= 235)
xgboost_test <- full_data_ipt_miss_wo_scale_add_three %>% filter(rank > 235)3.5.3 dmatrix
library(xgboost)
get_dmatrix <- function(x){
xgb.DMatrix(data = as.matrix(x %>% select(-code,-return)),
label = x$return)
}
xgboost_dtrain <- get_dmatrix(xgboost_train)
xgboost_dvalid <- get_dmatrix(xgboost_valid)
xgboost_dtest <- get_dmatrix(xgboost_test)
watchlist <- list(train = xgboost_dtrain,
test = xgboost_dvalid)3.5.4 modeling
xgb <- xgb.train(
data = xgboost_dtrain,
# 1
eta = 0.1,
nround = 2000,
# 这里也是没有办法,为了调整参数,所以设置了很高的学习率,nround少于100次
# 最后可以尝试更低的。
# 2
max_depth = 7,
min_child_weight = 17,
gamma = 0.72,
# 3
subsample = 0.8,
colsample_bytree = 0.95,
# 评价标准
# eval.metric = "error",
# eval.metric = "rmse",
# eval.metric = ks_value,
# eval.metric = "auc",
# eval.metric = "logloss",
# objective
objective = "reg:linear", # 这是一个回归问题
# 其他
seed = 123,
watchlist = watchlist,
# 300万数据一起用!
nfold = 5,
early.stop = 50,
nthread = 8
)library(pryr)
object_size(xgb)
xgb.save(xgb, file.path("data","round4_files","fcontest_xgboost.model"))3.5.5 perf
fcontest_xgb <- xgb.load(file.path("data","round4_files","fcontest_xgboost.model"))library(xgboost)
length(predict(fcontest_xgb,xgboost_dvalid))
dim(xgboost_valid)xgboost_valid_add_yhat <-
xgboost_valid %>%
select(rank,code,return) %>%
add_column(return_pred = predict(fcontest_xgb,xgboost_dvalid))xgboost_30_list <-
xgboost_valid_add_yhat %>%
group_by(rank) %>%
top_n(50,return_pred) %>%
ungroup() %>%
group_by(code) %>%
count() %>%
ungroup() %>%
arrange(desc(n)) %>%
top_n(30,n) %>%
write_csv(file.path("data","round4_files","xgboost_30.csv"))xgboost_30_list3.6 xgboost add lag y
3.7 xgboost classification
3.8 引入相关性
使用最好的的结果"naive_30_3.0.csv",进行分析。
library(tidyverse)
library(reshape2)
cor_list <- function(x) {
L <- M <- cor(x)
M[lower.tri(M, diag = TRUE)] <- NA
M <- melt(M)
names(M)[3] <- "points"
# lower.tri就是i比j大,而已。
L[upper.tri(L, diag = TRUE)] <- NA
L <- melt(L)
names(L)[3] <- "labels"
merge(M, L)
}
read_csv(file.path("data","round4_files","naive_30_3.0.csv")) %>%
select(code) %>%
left_join(full_data_ipt_miss_add_return, by = "code") %>%
select(code,rank,return) %>%
spread(code,return) %>%
select(-rank) %>%
do(cor_list(.)) %>%
select(1:3) %>%
filter(!is.na(points)) %>%
group_by(Var1) %>%
summarise(avg_cor = mean(points),sd_cor = sd(points),
z_cor = avg_cor/sd_cor) %>%
arrange(abs(z_cor))
# arrange(z_cor)
# arrange(sd_cor)- round1:
- z-score:
- min:
stock103391 - max:
stock103501 - 0 :
stock102682,有效。
- min:
- sd:
stock103445
- z-score:
- round2:
- z-score:
- min:
stock102109 - max:
stock102853 - 0 :
stock101653,有效。
- min:
- sd:
stock102253
- z-score:
read_csv(file.path("data","round4_files","naive_30_3.0.csv")) %>%
filter(code != "stock102109") %>%
write_csv(file.path("data","round4_files","cor_z_score_lower.csv"))
read_csv(file.path("data","round4_files","naive_30_3.0.csv")) %>%
filter(code != "stock102853") %>%
write_csv(file.path("data","round4_files","cor_z_score_upper.csv"))
read_csv(file.path("data","round4_files","naive_30_3.0.csv")) %>%
filter(code != "stock101155") %>%
write_csv(file.path("data","round4_files","cor_z_score_zero.csv"))
read_csv(file.path("data","round4_files","naive_30_3.0.csv")) %>%
filter(code != "stock102253") %>%
write_csv(file.path("data","round4_files","cor_sd_lower.csv"))3.8.1 增加p值
我更新了各个股票之间的相关性情况,之前只有相关系数\(\rho\),没有显著水平,因此可能产生误导。 我的打算是,选取\(\rho>0.8\)并且\(\text{p value} < 0.05\)的股票作为研究。 这个数据怎么用我也没想好,我起初想,如果我们选择上传的的股票中,对应的显著正相关的股票没有选择的话,我们可以看看什么原因导致我们没选上这个显著正相关的股票。
这让我想到了,我们应该反馈下\(\alpha和\beta\)的p value,否则很高的\(\alpha和\beta\),但是显著水平低,我们也不能进我们的篮子里面。
昨天我记得要分别传模型的预测值\(\hat y_{i,t}\),作为另一个模型的\(x\)变量,我们这里应该把\(\hat y\)的p value也反馈了。因为似乎我们选择少的时间,比如11期,可以得到很好的\(\hat y\),但是不一定显著的,我们还要看看我们的\(\hat y\)的显著水平,我猜想,我们选择少的时间,必然p值不高,我们可以在这上做一些权衡。
library(tidystringdist)
code_comb <-
full_data_ipt_miss_add_return %>%
distinct(code) %>%
.$code %>%
tidy_comb_all()return_spread <-
full_data_ipt_miss_add_return %>%
select(rank,code,return) %>%
spread(code,return) %>%
select(-rank)code_comb_cor <-
code_comb %>%
pmap(~ cor.test(return_spread[[.x]], return_spread[[.y]])) %>%
map_df(broom::tidy) %>%
bind_cols(code_comb, .)estimate: 相关系数\(\rho\)statistic: 显著值,类似于t-valuep.value: 显著水平, p-value,越小越好。
code_comb_cor %>% write_csv(file.path("data","round4_files","code_comb_cor.csv"))library(pryr)
object_size(code_comb_cor)4 检验模型效果
test_data <-
full_data_ipt_miss_wo_scale %>%
filter(rank > 235) %>%
select(rank,code,return)这里\(t \in [1,353]\),其中\(t \in [236,353]\)作为测试组。
4.1 Geometric Mean Return
\[\bar r_g = \prod_{i=1}^{353}(1+r_i)-1\]
idea主要参考 Boudt, Dirick, and Parry (n.d.), 构建参考: r - Geometric Mean: is there a built-in? - Stack Overflow
gmean_r <- function(x){(exp(mean(log(x/100+1)))-1)*100}这里的x的单位是%
model_proc <- function(x){
x <- file.path("round2_files",x)
code_blanket <-
read_csv(x) %>% select(code)
model_table <-
code_blanket %>%
left_join(test_data,by="code") %>%
select(code,rank,return)
model_perf <-
model_table %>%
summarise(gmean_r(return)) %>%
pull()
model_perf_text <- paste(x,":",as.character(round(model_perf*10000)/10000),"%")
return(list(code_blanket,model_table,model_perf_text))
}model_proc是一个list,第一项是选择的code,第二项是left join的rank和return后的表,第三项是平均收益率。
naive_30 <- model_proc("naive_30.csv")
naive_30_2.0 <- model_proc("naive_30_2.0.csv")
naive_30_3.0 <- model_proc("naive_30_3.0.csv")
naive_30_4.0 <- model_proc("naive_30_4.0.csv")
mu_sigma_30 <- model_proc("mu_sigma_30.csv")
# biglm_alpha_top_30 <- model_proc("biglm_alpha_top_30.csv")
# biglm_alpha_top_30_return_only <- model_proc("biglm_alpha_top_30_return_only.csv")
# wu_20180401 <- model_proc("wu_20180401.csv")
# wu_20180402 <- model_proc("wu_20180402.csv")
# wu_20180402_2 <- model_proc("wu_20180402_2.csv")
# wu_20180404 <- model_proc("wu_20180404.csv")
# wu_20180405 <- model_proc("wu_20180405.csv")
# xiaosong_20180405 <- model_proc("xiaosong_20180405.csv")
xgboost_30 <- model_proc("xgboost_30.csv")
history_ensemble <- model_proc("history_ensemble.csv")naive_30[[3]]
naive_30_2.0[[3]]
naive_30_3.0[[3]]
naive_30_4.0[[3]]
mu_sigma_30[[3]]
# biglm_alpha_top_30[[3]]
# biglm_alpha_top_30_return_only[[3]]
# wu_20180401[[3]]
# wu_20180402[[3]]
# wu_20180402_2[[3]]
# wu_20180404[[3]]
# wu_20180405[[3]]
# xiaosong_20180405[[3]]
xgboost_30[[3]]
# history_ensemble[[3]]我验证了一波,的确第一次的收益率在测试组中是最高的,37%%半年收益率。我发现,单规则粗暴一点效果还可以,
但是加入X后,不能粗暴的跑biglm,结果非常差,收益率几乎为0.
跑模型一定要精细化。
add_name <- function(x,y){
x[[1]] %>% mutate(type = y)
}code_selection_by_all_model_long <-
bind_rows(
add_name(naive_30,"naive_30"),
add_name(naive_30_2.0,"naive_30_2.0"),
add_name(naive_30_3.0,"naive_30_3.0"),
add_name(naive_30_3.0,"naive_30_4.0"),
add_name(mu_sigma_30,"mu_sigma_30"),
# add_name(biglm_alpha_top_30,"biglm_alpha_top_30_code"),
# add_name(biglm_alpha_top_30_return_only,"biglm_alpha_top_30_code_return_only"),
# add_name(wu_20180401,"wu_20180401"),
# add_name(wu_20180402,"wu_20180402"),
add_name(xgboost_30,"xgboost_30"),
add_name(history_ensemble,"history_ensemble")
)
code_selection_by_all_model_wide <-
code_selection_by_all_model_long %>%
mutate(value = 1) %>%
spread(type,value)4.2 历史平均法
history_ensemble <-
code_selection_by_all_model_long %>%
group_by(code) %>%
count() %>%
arrange(desc(n)) %>%
ungroup() %>%
top_n(30,n) %>%
write_csv(file.path("data","round4_files","history_ensemble.csv"))history_perf <-
test_data %>%
group_by(code) %>%
summarise(mean = mean(return),sd = sd(return)) %>%
arrange(desc(mean),sd) %>%
left_join(code_selection_by_all_model_wide, by = "code") %>%
write_csv(file.path("data","round4_files","history_perf.csv"))
history_perf %>% head(10)这里的mean表示测试组中,平均收益率,sd是对应的标准差,
这里按照从高到低先排序mean,再从低到高排序sd。
type*表示四种方法是否选择这些股,理论上越好的选择,越选择靠前的股票。
save.image()参考文献
Boudt, Kris, Lore Dirick, and Josiah Parry. n.d. “Https://Www.datacamp.com/Courses/Introduction-to-Portfolio-Analysis-in-R.” DataCamp.
Conway, Drew, and John White. 2012. Machine Learning for Hackers Case Studies and Algorithms to Get You Started. O’Reilly Media. http://shop.oreilly.com/product/0636920018483.do.
DataCastle小运营. 2018. “【赛事Q&A】凤凰金融量化投资大赛.” 2018. http://www.dcjingsai.com/common/bbs/topicDetails.html?tid=1033.
Hilpisch, Yves. 2014. Python for Finance: Analyze Big Financial Data. O’Reilly Media, Inc.
Kleiber, Christian, and Achim Zeileis. 2008. Applied Econometrics with R. Springer New York.
Li, Jiaxiang. 2018. “Tidyquant 使用技巧.” 2018. https://jiaxiangli.netlify.com/2018/04/tidyquant.
Nicholson, Walter, and Christopher Snyder. 2011. “Microeconomic Theory: Basic Principles and Extensions, 11th Edition” 44 (4): 370–72.
Regenstein, Jonathan. 2018. “Calculating Beta in the Capital Asset Pricing Model.” 2018. https://rviews.rstudio.com/2018/02/08/capm-beta/.
Schutt, Rachel, and Cathy O’Neil. 2013. Doing Data Science: Straight Talk from the Frontline. O’Reilly Media, Inc.
Wickham, Hadley. 2014. Advanced R. Chapman; Hall/CRC.
Wickham, Hadley, and Garrett Grolemund. 2017. R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. O’Reilly Media, Inc.
彭堃. 2017. “机器学习之Logistic选股模型初探——基于沪深300.” 2017. https://mp.weixin.qq.com/s/0tqE1YNc5QaokX1q8nT0OA.
戴军, 黄志文, and 葛新元. 2010. Logistic选股模型及其在沪深300中的实证. 国信证券.
林晓明, 陈烨, and 李子钰. 2018. 人工智能选股之stacking集成学习. 华泰证券股份有限公司.
狗熊会. 2018. “基于业绩持续性的初步探讨.” 2018. https://mp.weixin.qq.com/s/jKprPY-UpvSPRT68zVhYpQ.