r_code
ch1
这个人写的书不错 * csgillespie/efficientR: Efficient R programming: a book 查看他的GitHub https://github.com/csgillespie
you need to know how long it takes to run. introduces the idea of benchmarking your code.
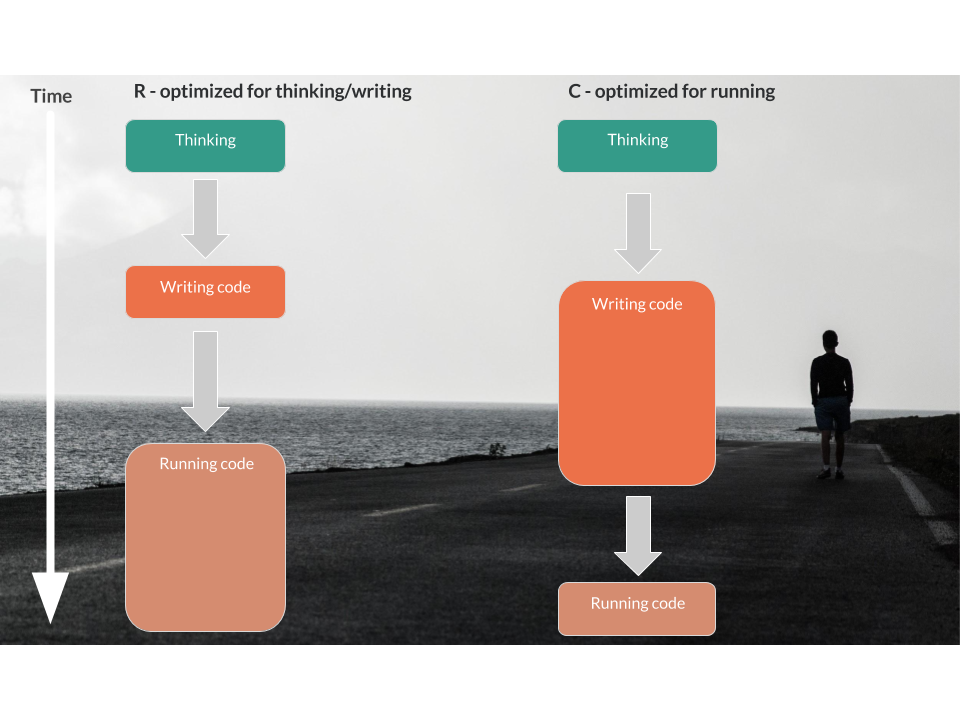
- R optimizing for writing
- C optimizing for running
因此说 C 比 R 快就弃用 R,是不科学的,我们需要比较 total time。 简单来说,比较 C 和 R 导入 csv
文档的步骤。
library(tidyverse)
## -- Attaching packages --------------------------------------------- tidyverse 1.2.1 --
## √ ggplot2 3.1.0 √ purrr 0.2.5
## √ tibble 1.4.2 √ dplyr 0.7.8
## √ tidyr 0.8.2 √ stringr 1.3.1
## √ readr 1.2.1 √ forcats 0.3.0
## -- Conflicts ------------------------------------------------ tidyverse_conflicts() --
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()
library(data.table)
##
## Attaching package: 'data.table'
## The following objects are masked from 'package:dplyr':
##
## between, first, last
## The following object is masked from 'package:purrr':
##
## transpose
knitr::include_graphics('pic/R_vs_C.png')
systime.time
system.time的定义
usertime is the CPU time charged for the execution of user instructions.systemtime is the CPU time charged for execution by the system on behalf of the calling process.- (\text{user} + \text{system} = \text{elapsed}) user 和 system 怎么理解?
<-和=的区别
Argument passing 和 Object assignment
<-都含有=只有其一,因此容易报错
colon <- function(n) 1:n
system.time(res <- colon(1e8))
## user system elapsed
## 0 0 0
system.time(expr = res <- colon(1e8))
## user system elapsed
## 0 0 0
# system.time(res = colon(1e8))
# Error in system.time(res = colon(1e+08)) : 参数没有用(res = colon(1e+08))
system.time(expr, gcFirst = TRUE)里面没有参数resexpr- R Expression, 因此用于评价R表达代码的。
system.time(res <- colon(1e8))=system.time(expr = res <- colon(1e8))
microbenchmark
microbenchmark 包参数和函数作用。 避免自己手写 for loop 和 system.time
colon <- function(n) 1:n
seq_default <- function(n) seq(1, n)
seq_by <- function(n) seq(1, n, by = 1)
library(microbenchmark)
n <- 1e5
microbenchmark(
colon(n)
,seq_default(n)
,seq_by(n)
,times = 10
)
## Unit: nanoseconds
## expr min lq mean median uq max neval
## colon(n) 0 0 130499.7 1026.5 3692 1289816 10
## seq_default(n) 6974 8616 213451.5 20717.5 115690 1497811 10
## seq_by(n) 1163049 1285303 1582362.5 1474016.5 1671756 2751524 10
read.csv vs readRDS
start_time <- Sys.time()
compare <-
microbenchmark(
read.csv('data/movies.csv')
,read_csv('data/movies.csv')
,fread('data/movies.csv')
,readRDS('data/movies.rds')
,read_rds('data/movies.rds')
,times = 10
) %>%
write_excel_csv('output/read_function_time.csv')
end_time <- Sys.time()
end_time - start_time
# Time difference of 10.29 secs
read_csv('output/read_function_time.csv') %>%
ggplot(aes(expr,time/1000000000)) +
# because the microbenchmark unit is nano-second
# 1000000000 nanosecond = 1 second
geom_boxplot() +
theme_bw() +
theme(axis.text.x = element_text(angle = 70, hjust = 1)) +
labs(
caption = "Made by Jiaxiang Li\nRound data with 10 times"
,x = "different read function"
,y = "time cost (s)"
,title = "fread is best!"
)
## Parsed with column specification:
## cols(
## expr = col_character(),
## time = col_double()
## )
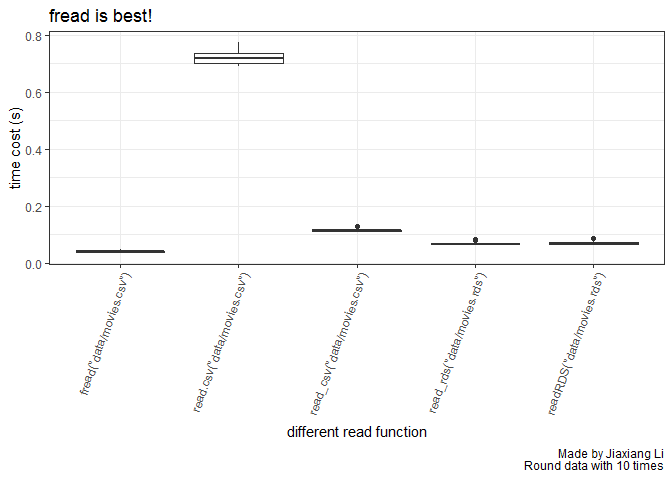
推荐使用fread
测试电脑
正如之前作者所说 更新最新版本的R,会让代码运行更快。 电脑的配置也会影响代码运行速度。
函数运行测试
library(benchmarkme)
res <- benchmark_std(runs = 3)
plot(res)
upload_results(res)
# PC laptop
res %>%
write_excel_csv('output/test_work_laptop.csv')
# PC desktop
res %>%
write_excel_csv('output/test_work_desktop.csv')
- 这里面都是一些数据集,进行电脑的测试。
- 封装了
system.time函数
fread('output/test_work_laptop.csv') %>%
select(1:3) %>%
summarise_all(funs(sum(.)))
## user system elapsed
## 1 114.1 0.87 115.84
fread('output/test_work_desktop.csv') %>%
select(1:3) %>%
summarise_all(funs(sum(.)))
## user system elapsed
## 1 95.96 1.11 97.51
显然研发机会更快。
电脑配置
# Load the benchmarkme package
library(benchmarkme)
# Assign the variable ram to the amount of RAM on this machine
get_ram()
## 17.2 GB
# Assign the variable cpu to the cpu specs
get_cpu()
## $vendor_id
## [1] "GenuineIntel"
##
## $model_name
## [1] "Intel(R) Core(TM) i5-6300U CPU @ 2.40GHz"
##
## $no_of_cores
## [1] 4
读写能力
# Load the package
library(benchmarkme)
# Run the io benchmark
res <- benchmark_io(runs = 1, size = 5)
# Plot the results
plot(res)
- 不需要尝试>50MB,因为电脑测试不了。
res %>%
write_excel_csv('output/test_work_laptop_wr.csv')
fread('output/test_work_laptop_wr.csv')
## user system elapsed test test_group cores
## 1: 0.89 0.00 0.89 read5 read5 0
## 2: 1.90 0.03 1.95 write5 write5 0